

Research at AImageLab covers topics of Computer Vision, Pattern Recognition & Machine Learning, Artificial Intelligence, and Multimedia applied to optical images and videos as well as data from different sensors. In addition, AImageLab is currently involved in research activities on vision-based human-computer interaction.
The main research projects concern: Video surveillance, Machine vision and robot vision, Medical imaging, Human-centered Multimedia, Content-based retrieval, People detection and tracking, Human behaviour understanding, Egocentric vision and Embedded sensors.






News
"Artificial Intelligence and opportunities for industry" seminar · 05 Apr 2024

On April 5th, prof. Rita Cucchiara held a seminar at Unindustria Reggio Emilia entitled "Artificial Intelligence and opportunities for industry".
You can find the slides at the following link: AI_unindustria_cucchiara.pdf
FAIR Workshop on Italian Visual and Language models: challenges and activities · 20 Jan 2024

On February, 5th 2024, AImageLab will host the FAIR Workshop on Italian Visual and Language models, as part of the FAIR "Future AI Research" project and of its transveral project on Vision, Language and Multimodal Challenges. See the dedicated page for further details.
Invited talk at "Intelligenza Artificiale e sapienza del cuore: per una comunicazione pienamente umana" · 13 Jan 2024

On January 13th, Prof. Rita Cucchiara has given a talk entitled "Sull'Intelligenza Artificiale Generativa" at the congress "Intelligenza Artificiale e sapienza del cuore: per una comunicazione pienamente umana", which took place in Reggio Emilia.
More details about the talk can be found at this link
Elise Catalogue of AI Centers · 08 Jan 2024

We are proud to announce that AImageLab and AIRI are included in the ELISE Catalogue of AI Nodes.
As part of the ELISE project, Spinverse developed a catalogue with nearly 100 research nodes for artificial intelligence from all European countries. The aim of the catalogue is to help students, scientists, and enterprises to discover the AI opportunities, both locally and in the rest of Europe. The catalogue includes excellence research nodes that belong to academia, have dedicated and informative websites.
"Robotics, AI and Ethics" Workshop at the Embassy of Italy, London (November 28th, 2023) · 28 Nov 2023

On November 28th, Prof. Rita Cucchiara will give an invited talk entitled "Detecting Fakes and Hallucinations for Responsible Generative AI" at the "Robotics, AI and Ethics" workshop, which will take place at the Embassy of Italy in London (UK).
More details about the workshop can be found at this link.
This workshop is connected to recent initiatives on Responsible Generative AI carried out within the ELIAS (European Lighthouse of AI for Sustainability) project, funded by the European Commission.
ToothFairy Challenge @ MICCAI 2023 · 19 Oct 2023

The first edition of the ToothFairy challenge, organized by the University of Modena and Reggio Emilia with the collaboration of Radboud University Medical Center, has been presented during the 26th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2023) held last week in Vancouver.
This competition brought together researchers from across the globe to tackle the Inferior Alveolar Canal (IAC) segmentation in CBCT volumes. The IAC is a vital anatomical structure that plays a significant role in oral and maxillofacial surgery. Precise segmentation of this structure is crucial for a wide range of clinical applications, from dental implant planning to nerve damage prevention during surgeries.
The complete leaderboard is available on the Grand-Challenge platform.
We are already working on the second edition of the challenge, ToothFairy2, which will involve additional anatomical structures making the competition even more challenging and with a broader impact on clinical practice.

Congratulazioni a Marcella e Lorenzo da parte di tutto AImageLab · 09 Oct 2023

Foundation stone-laying ceremony for the Center for Artificial Intelligence and Vision · 16 Sep 2023

We are happy to announce that on Sept. 20th, at 9.00 am it will take place the ceremony for the laying of the foundation stone of the new Center for Artificial Intelligence and Vision (CAIV) at the Department of Engineering "Enzo Ferrari" (room MO25-P0.4 and onsite), with the participation of:
- Carlo Adolfo Porro - Dean of UniMORE
- Massimo Borghi - Director of the Department of Engineering "Enzo Ferrari" UniMORE
- Rita Cucchiara - Director of the AIRI Center UniMORE
- Cees Snoek - Director of Amsterdam AI, University of Amsterdam
- Stefano Savoia - Director of the Direzione Tecnica UniMORE
- Franco Vitali - EFFE-GI Impianti s.r.l.
- Stefano Bonaccini - President of Regione Emilia-Romagna
The CAIV is a new infrastructure that will be built next to the Technopole of Modena and is the result of the collaboration between the AImageLab laboratory of the Department of Engineering "Enzo Ferrari" of Unimore, the Interdepartmental Artificial Intelligence Research and Innovation (AIRI) Centre of Unimore, the Emilia Romagna Region, and the European Labs of Learning and Intelligent Systems (ELLIS) European Network of Excellence. It is designed to be a center of excellence capable of hosting both researchers and companies, equipped with modern research spaces and coworking areas. The CAIV will be a major incubator for international scientific projects and innovative technology transfer activities in the field of Artificial Intelligence and Computational Vision.
See you there!
ELLIS Summer School on Large-Scale AI - Social event hosted by Florim Ceramiche SpA · 16 Sep 2023

We are very grateful to Florim Ceramiche SpA for sponsoring the ELLIS Summer School on Large-Scale AI and hosting its social event on Tuesday,19th September in the in the Florim Gallery in Fiorano Modenese!
During the event, Cristian Canton Ferrer, Head of Responsible AI, Meta will give a keynote talk on "Responsible AI in the age of GenAI: the case of Llama2" and Prof. Rita Cucchiara, Director of the AIRI Centre, UniMORE will moderate a Round Table on "Artificial Intelligence a big opportunity in Industry", with the participation of
- Stefano Bonaccini, President of Regione Emilia-Romagna
- Michela Milano, Director of the Alma Mater Research Institute for Human-Centered Artificial Intelligence, University of Bologna
- Industrial discussion with:
- Tetra Pak SpA: Paolo Scarabelli, Automation and Digital Innovation Director and Sara Egidi, Automation and Digital Innovation
- Florim SpA: Luca Sghedoni, Head of Data Intelligence
- E4 Computer Engineering: Marco Cicala, CTO
- expert.ai: Stefano Spaggiari, Executive Chairman
- Digital Design: Andrea Mariani, Head of R&D
All the information about the event can be found here!
AImageLab@ICDAR2023 · 16 Aug 2023

We are happy to announce that AImageLab will participate in the International Conference on Document Analysis with an oral presentation of the paper How to Choose Pretrained Handwriting Recognition Models for Single Writer Fine-Tuning by Vittorio Pippi, Silvia Cascianelli, Christopher Kermorvant, Rita Cucchiara, and the ADAPDA workshop (Workshop on Automatically Domain-Adapted and Personalized Document Analysis) organized by Rita Cucchiara, Eric Anquetil (University of Rennes), Christopher Kermorvant (University of Rouen & TEKLIA spa), and Silvia Cascianelli!
AInageLab on lepida TV! · 04 Jul 2023

AImageLab members are the protagonists of the 'Helloworld' episode, online on Lepida TV, dedicated to 'Big Data and AI, projects and people in Emilia-Romagna'.
Check out the video here!
7 PhD Positions in Computer Vision at AImageLab · 02 Jul 2023

The AImageLab Research Group at the Department of Engineering “Enzo Ferrari” of the University of Modena and Reggio Emilia (Italy) has 7 fully funded PhD positions in Computer Vision. Each PhD position is covered by a 3-year grant, funded by the Italian Ministry of Research and University.
Some positions will be open at the International PhD School in ICT of the University of Modena and Reggio Emilia and others under the National PhD Program in Artificial Intelligence of the University of Pisa, with the University of Modena and Reggio Emilia as the hosting university. The call will require a CV, a research statement, and possibly presentation letters.
During the PhD, there will be the possibility of carrying out a 6-month internship abroad and having connections with ELLIS (European Labs of Learning and Intelligent Systems).
The topics are (flexible):
-
Visual and Language Large-scale Models
-
New Unlearning Models in Computer Vision
-
Personalized Human-Robot Interaction and Visual Language Navigation
-
Language Models and Document Processing for Public Administration
-
Human Analysis and Video Captioning
-
DeepFake Image Detection and Generative AI
-
Finance Time Series Generative and Discriminative Models
Requirements:
A Master’s degree in Computer Science is required for the application, to be obtained by October 31st, 2023. Applicants should have a strong background in Computer Science and excellent programming skills (e.g. Python). Previous knowledge of Deep Learning frameworks (e.g. PyTorch, TensorFlow) is desirable.
How to Apply:
Interested candidates should send their CV to rita.cucchiara@unimore.it and segreteria.aimagelab@unimore.it.
Application Deadline ICT: July 27th, 2023 [link]
Application Deadline National PhD Program in AI: soon published
Start of the PhD Course: November 1st, 2023
AImageLab and AIRI at R2B 2023 · 16 Jun 2023

Prof. Roberto Vezzani represented AIRI during the R2B event, presenting the Fit4MedRob project during the assembly of the Clust-ER Health.
During R2B there was also the technical committees meeting and, subsequently, the assembly of the National Technology Cluster SmartCommunitiesTech, in which Prof. Vezzani participated as a member of the Scientific Technical Committee. The roadmap document of the entire Cluster is being updated; part of the revision has been entrusted to the CTS in the coming months. Therefore, those who would like to contribute or be informed on the subject can refer to Prof. Vezzani.
Prof. Balboni coordinated the event "The role of the university in the development of skills and talents - Educating entrepreneurship: business ideas for sustainable and inclusive mobility of the TACC Unimore program", where the business ideas that are developing within the fourth edition of the programme, covering various innovative aspects for a new sustainable mobility, were presented. Students of the master’s degrees in Computer Engineering and Electronics and of AImageLab also presented their work.
Invited lecture at the Summer School of the PhD School on AI and Society · 06 Jun 2023

Prof. Rita Cucchiara is giving an invited talk at the Summer School of the PhD School in “AI and Society” (La Maddalena, Italy), on "Challenges in Computer Vision, NLP and Generative AI".
Slides are available here.
Invited lecture by Prof. Laura Leal-Taixé · 20 May 2023

On Wednesday, May 24th, at 3:00 p.m., Laura Leal-Taixé (NVIDIA, Technical University of Munich) will give an invited lecture on Multi-Object Tracking. The event is organized as part of the Computer Vision and Cognitive System course and will be held in room P1.5 of the Engineering Department "Enzo Ferrari".
AIDA e-lecture: "From Images to Text: New forms of Human-AI Interaction" by Lorenzo Baraldi - May 16th · 10 May 2023

We are pleased to announce that our own Lorenzo Baraldi will deliver for the International AI Doctoral Academy (AIDA) the e-lecture: “From Images to Text: New forms of Human-AI Interaction”, on May 16th, 2023 17:00 -18:00 CET. See details in: http://www.i-aida.org/ai-lectures/
You can join for free using the zoom link: link & Password: 148148
DDGan project, Digital Design Generative Adversarial Networks · 13 Apr 2023

We are proud to present the result of the collaboration between AImageLab and Digital Design: the DDGan project, Digital Design Generative Adversarial Networks, a patented artificial intelligence system for the creation of digital images for surface printing.
The system, during the training phase, analyzes fragments of scans of different natural materials (selected by designers), such as marble or precious woods, understanding their specific characteristics and distinctive elements. At the end of this phase, the neural network is able to generate new images, highly realistic and indistinguishable from the real materials. Starting from the image of a material, therefore, it is possible to obtain many other images very similar, but never equal to each other by composing a potentially infinite set of graphics.
This type of system represents a breakthrough for the industry, as it is able to operate images in a creative way opening the door to new incredible scenarios. Not only that, this also allows much less material to be scanned, making the graphics capture process much more environmentally friendly.
Here is it possible to see a short video of the project.
Prof. Cucchiara's DFKI webinar on "Artificial Intelligence: Methods and Applications" · 13 Apr 2023

On April 19th, 2023, from 10 to 11.30 am, Prof. Rita Cucchiara will give a webinar on "From visual to multimodal understanding", as part of the series Italy-Germany WEBinar Series (WEBS) – II: "Artificial Intelligence: methods and applications", organized by CNR and DFKI, on the subject of 'Vision, Language, and multimodal challenge'.
To participate, register at: https://register.gotowebinar.com/register/5151391626275480408.
Papers Accepted at CVPR 2023 · 29 Mar 2023

We are very happy to announce that the following papers have been accepted to CVPR 2023, that will take place from June 18th to June 22th in Vancouver (Canada).
- "Positive-Augmented Contrastive Learning for Image and Video Captioning Evaluation" (highlight)
by S. Sarto, M. Barraco, M. Cornia, L. Baraldi, R. Cucchiara
[paper] [code]
- "Handwritten Text Generation from Visual Archetypes"
by V. Pippi, S. Cascianelli, R. Cucchiara
[paper] [code]
- "Masked Jigsaw Puzzle: A Versatile Position Embedding for Vision Transformers"
by B. Ren, Y. Liu, Y. Song, W. Bi, R. Cucchiara, N. Sebe, W. Wang
[paper]
ELLIS Summer School on Large-Scale AI - 18th-22nd September · 24 Mar 2023

We are proud to announce that the Modena Elllis Unit will be organizing a Summer School of the Ellis network this year, on September 18th to 22nd, at Modena Technopole.
The 2023 ELLIS "Summer School on Large-Scale AI" is an annual event for ELLIS PhD students, post-docs and fellows to meet in person and share knowledge about Machine Learning, Intelligent Systems and all topics covered by the ELLIS Programs.
The theme of the lectures and keynotes of this edition will be “Large-Scale AI for Research and Industry”.
The school will focus on advanced scientific research and on the exploitation of European GPU-based HPC facilities. As our research has strong implications and applications in industry, we will also discuss with representatives of industrial research labs.
Students of the School will have the opportunity to:
- attend high-profile lectures and tutorials from top-level scientists
- attend lab lectures from both academia and industry
- discuss their work through poster and tooling sessions
- develop projects on the parallel GPU facilities of the Leonardo Supercomputer hosted by CINECA
- have fun!
Open call: ELSA is funding innovative industry projects on safe and secure AI · 09 Mar 2023

Open Call: The best 6 SEMs/Startups developing novel AI-based applications and services will be supported with up to 60,000 Euros. Apply before the 31st of May, 2023 at 13:00 o´clock.
ELSA - European Lighthouse on Safe and Secure AI connects the best artificial intelligence and machine learning researchers from across Europe to make AI solutions safe and foster applicability. The growing network builds on and extends ELLIS, an internationally recognized pan-European AI network of excellence. Now, ELSA is looking for SEMs and Startups to collaborate on methods, software solutions, or benchmarks into applications and services, bringing them into industrial use.
Join ELSA for a 6-month program funded by the European Union and receive:
• Up to € 60.000 (lump sum) to develop AI/Machine Learning applications
• Visibility through ELSA online channels and events, and dissemination in the ELSA community.
What kind of projects are we looking for?
ELSA is looking for projects based on AI applications that engage with the network in the categories “Methodology”, “Software/Tools”, “Benchmarks” relevant but not limited to ELSA’s 6 use cases (see list below) in the scope of safe and secure AI. ELSA is focused on 3 research programs but applications are not limited to them as long as the proposals will address high impact societal and economic challenges using machine learning.
Use Cases:
- Health
- Autonomous Driving
- Robotics
- Media Analytics
- Cybersecurity
- Document intelligence
More about the use cases: https://www.elsa-ai.eu/use_cases.html
Apply here: https://www.f6s.com/european-lighthouse-on-safe-secure-ai/apply
Evento "AI, unplugged" · 03 Mar 2023

AimageLab, in collaborazione con AI Academy, ha il piacere di invitarvi all'evento “AI, unplugged - Ingegneria dell’intelligenza artificiale, un nuovo corso accanto all’impresa”, il giorno 3 Marzo alle ore 9:00 presso il Tecnopolo di Modena in Via Vivarelli 2. La giornata nasce dall’esigenza di presentare al tessuto produttivo del territorio e al pubblico il nuovo corso di laurea magistrale su Artificial Intelligence Engineering presso il Dipartimento di Ingegneria Enzo Ferrari dell’Università di Modena e Reggio Emilia.
Tale corso risponde all’esigenza di affrontare le complesse tematiche legate all’ingegneria dei sistemi intelligenti, fornendo competenze teoriche e applicative volte alla progettazione e all’integrazione dei sistemi di AI del futuro. Il corso, interamente in lingua inglese, nasce in stretta cooperazione con importanti realtà del panorama italiano e internazionale e offre una piattaforma aperta di stretta cooperazione tra accademia e impresa: nel corso della giornata verranno perciò presentate le opportunità di collaborazione tra imprese e università all’interno del nuovo corso di studi in termini di tirocini, didattica frontale e attività di accompagnamento al mondo del lavoro. La presentazione del corso avverrà all’interno di un evento di divulgazione focalizzato sull’AI e le sue differenti applicazioni nel mondo della ricerca, formazione e impresa. Verrà inoltre rinnovata la collaborazione con NVIDIA che rafforza la presenza di aziende internazionali sul territorio della regione attraverso il laboratorio congiunto NVAITC.
Programma completo alla pagina https://www.aiacademy.unimore.it/ai-unplugged/ e nel relativo allegato.
VIDEO dell'evento
La partecipazione è gratuita con registrazione obbligatoria qui
PERSEO Meeting at UNIMORE · 21 Feb 2023

We are pleased to announce the Perseo Meeting that will take place in Modena, Italy February 21-23, 2023.
To join Zoom Meeting:
https://herts-ac-uk.zoom.us/j/94460723107?pwd=NXBLWWM5YTE3Z1UwT3Z3YWN2NmFTUT09
Meeting ID: 944 6072 3107
Passcode: 267102
Complete meeting schedule here
IEEE Computer special issue on trustworthy AI · 15 Feb 2023

We are proud to announce an IEEE Computer special issue on trustworthy AI, with, the participation, as guest editors, of: Riccardo Mariani (Nvidia), Francesca Rossi, T.J. Watson (IBM Research Lab), Rita Cucchiara (Università di Modena e Reggio Emilia), Marco Pavone (Stanford University and Nvidia), Barnaby Simkin (Nvidia), Ansgar Koene (University of Nottingham), Jochen Papenbrock (Nvidia).
The complete issue can be found here
Post-Doc Position at the University of Modena and Reggio Emilia in Deep Learning for Multimodal and Tabular Data · 01 Feb 2023

The Department of Computer Engineering at the University of Modena and Reggio Emilia (Italy) is seeking candidates for a two-year Post-Doc position in Deep Learning for Multimodal and Tabular Data. Specifically, the research will focus on both Vision-Language models and Tabular data, where the latter are typically composed of structured data extracted from tabular datasets and represent an emerging area of interest in Artificial Intelligence.
There are no teaching duties, and all the work is research-oriented, including obligations with regard to publications/scientific communications. A PhD in Deep Learning or related areas (e.g., Computer Vision, Natural Language Processing, etc) is required. The position is funded by CNR (the national research council) in the Fair - Future AI research - Next generation Europe- project.
Read more about the Department at: https://www.ingmo.unimore.it/site/en/home.html
For additional information, you may contact Enver Sangineto (enver.sangineto@unimore.it).
To apply, please send your cv to enver.sangineto@unimore.it and rita.cucchiara@unimore.it
Paper Accepted at ICRA 2023 · 17 Jan 2023

We are happy to announce that we are going to present:
"Embodied Agents for Efficient Exploration and Smart Scene Description" by R. Bigazzi, M. Cornia, S. Cascianelli, L. Baraldi, R. Cucchiara (arxiv)
to the IEEE International Conference on Robotics and Automation (ICRA) that will be held in London from 29th May to 2nd June 2023.
Seminar "3D Computer Vision for animals", Silvia Zuffi - Gender Unbalanced AI · 15 Dec 2022

On Thursday, December 15th, at 2:15 p.m., Silvia Zuffi (IMATI-CNR) will give a talk on "3D Computer Vision for animals". The event is organized as part of a cycle of seminars "GENDER UNBALANCED AI" and will be held at the Sala Eventi Tecnopolo (Building 52) of the Engineering Department "Enzo Ferrari".
Complete list of the "GENDER UNBALANCED AI" seminars here
Abstract
Animals are an important resource for our society, but unfortunately they are often threatened and over exploited by humans. Computer vision can greatly contribute to animal conservation and wellbeing by providing non-invasive tools for capturing animai behaviour. Animals communicate mostly with body posture and sound, their health conditions are often related to shape changes. In this talk I will present my work on taking a 3D perspective when looking at animals, specifically through generative models of animal shape for 3D pose and shape reconstruction from monocular data.
More information can be found at this link.
You can also attend the seminar online via Microsoft Teams through this link.
Invited Talk at "Vision Transformers: Theory and Applications" workshop at NeurIPS 2022 · 09 Dec 2022

Rita Cucchiara gave an invited talk at the "Vision Transformers: Theory and Applications" workshop, organized in conjunction with NeurIPS 2022, about "Vision Transformers and their use in multimodal networks". The talk covers our recent architecural works on Vision Transformers and their application in multi-modal networks for Vision and Language integration.
The video of the talk can be found here.
Paper Accepted for publication on T-PAMI · 05 Dec 2022

We are happy to announce that our paper:
"Class-Incremental Continual Learning into the eXtended DER-verse" by M. Boschini, L. Bonicelli, P. Buzzega, A. Porrello, and S. Calderara [arxiv][github]
has been accepted for publication on IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI).
Paper Accepted at NeurIPS 2022 · 30 Nov 2022
We ae proud to announce that the paper "Maximum Class Separation as Inductive Bias in One Matrix" (Tejaswi Kasarla · Gertjan Burghouts · Max van Spengler · Elise van der Pol · Rita Cucchiara · Pascal Mettes) has been accepted as Oral Paper at NeurIPS 2022.
Seminar on GPU-Accelerated Computing · 28 Nov 2022

On Wednesday, November 30th, at 2:30 p.m., Giuseppe Fiameni (NVIDIA) will give an invited talk on "GPU-Accelerated Computing".
Giuseppe Fiameni is a Solution Architect and Data Scientist at NVIDIA, where he oversees the NVIDIA AI Technology Center in Italy, a collaboration among NVIDIA, CINI and CINECA to accelerate academic research in the field of Artificial Intelligence.
The seminar will be held at Aula S1, Cinema Raffaello, Via Formigina 280 - 41126 Modena.
More info on the seminar here
Seminar "From Handcrafted to End-to-End Learning, and Back: a Journey far Multi-Object Tracking" Laura Leal-Taixé - GENDER UNBALANCED AI · 28 Nov 2022
On Friday, December 2nd, at 2:15 p.m., Laura Leal-Taixé (NVIDIA, Technical University of Munich) will give a talk on "From Handcrafted to End-to-End Learning, and Back: a Journey far Multi-Object Tracking". The event is organized as part of a cycle of seminars "GENDER UNBALANCED AI" and will be held at the Sala Eventi Tecnopolo (Building 52) of the Engineering Department "Enzo Ferrari".
Complete list of the "GENDER UNBALANCED AI" seminars here
Abstract
The challenging task of multi-object tracking (MOT) requires simultaneous reasoning about track initialization, identity, and spatiotemporal trajectories.This problem has been traditionally addressed with the tracking-by-detection paradigm, but recent research has focused on more recent end-to-end leaming paradigms such as tracking-by-regression or tracking-by attention. In this talk I will discuss all the paradigms shifts only to circle back right where we started, tracking-by-detection. Can this paradigm be state-of-the-art?
More information can be found at this link.
You can also attend the seminar online via Microsoft Teams through this link.
Seminar "Graph Signal Processing for Machine Learning: Challenges and Use-cases", Laura Toni - Gender Unbalanced AI · 22 Nov 2022

On Tuesday, November 22nd, 2022 at 9:15 a.m., Laura Toni (Associate Professor at the University College of London - UCL) will give a talk on "Graph Signal Processing for Machine Learning: Challenges and Use-cases". The event is organized as part of a cycle of seminars "GENDER UNBALANCED AI" and will be held at the Sala Eventi Tecnopolo (Building 52) of the Engineering Department "Enzo Ferrari".
Abstract
The effective representation, processing, analysis, and visualization of large-scale structured data, especially those related to complex domains such as networks and graphs, are one of the key questions in modern machine learning. Graph Signal Processing (GSP), a vibrant branch of signal processing models and algorithms that aims at handling data supported on graphs, opens new paths of research to address this challenge. In this talk, we review a few important contributions made by GSP concepts and tools, such as graph filters and transforms, to the development of novel machine learning algorithms. We present this by proposing different research problems that are currently under investigation in our lab on decision making strategies (graph-based decision making strategies) and computer vision (space-time priors for point cloud prediction).
More information can be found at this link.
You can also attend the seminar online via Microsoft Teams through this link.
Paper Accepted at NeurIPS 2022 · 15 Nov 2022
We are happy to announce that we are going to present:
"On the Effectiveness of Lipschitz-Driven Rehearsal in Continual Learning" by L. Bonicelli, M. Boschini, A. Porrello, C. Spampinato, and S. Calderara [arxiv][github] (main conference, poster)
to the Neural Information Processing Systems (NeurIPS) that will be held in New Orleans from 28th October to 9th December 2022.
'Humanities & Intelligence' Lectio magistralis now online · 11 Nov 2022

The four Lectio magistralis of the 'Humanities & Intelligence' event:
- Prof. Mubarak Shah, Center for Research in Computer Vision, University of Central Florida (USA) “Open-World Semi-Supervised Learning”
- Prof. Alberto del Bimbo, Distinguished Professor, Media Integration and Communication Center, Università degli Studi di Firenze “AI Technology and Cultural Heritage: about Artificial Intelligence and Machines that See”
- Dr. Enrica Filippi, Principal Engineer, Core Machine Learning, Google.com (USA) “AI for social good”
- Prof. Maurizio Ferraris, Full Professor of Theoretical Philosophy, Università di Torino “Webfare. Giving Connections their Value”
are now online on our youtube channel! Complete videos here and here
'Humanities & Intelligence' event - November 4th, 2022 · 25 Oct 2022
We are proud to announce the 'Humanities & Intelligence' event, wich will be held on the Sala eventi at the Tecnopolo of Modena (Via Vivarelli 10/1) on November 4th, 2022, from 9:30 a.m. to 1 p.m.
The event will feature an exceptional parterre of scientific talks by distinguished researchers in the fields of Artificial Intelligence for cultural heritage and social challenges, like Mubarak Shah (Center for Research in Computer Vision, University of Central Florida), Enrica Filippi (Principal Engineer, Core Machine Learning, Google.com), Alberto Del Bimbo (Media Integration and Communication Center, University of Florence) and Maurizio Ferraris (Labont – Center for Ontology, University of Turin).
The event will be followed in the afternoon by dissemination workshops on Artificial Intelligence and Cultural Heritage, at AGO Modena.
The complete program can be found on the event website https://humanitiesandintelligence.com/
21 October 1672 - 21 October 2022: 350th Birth Anniversary of Lodovico Antonio Muratori · 21 Oct 2022

At AImageLab we wanted to homage Lodovico Antonio Muratori, whose work is so valuable also for our research!
Papers Accepted at ECCV 2022 · 14 Oct 2022

We are happy to announce that we are going to present these works:
"Transfer without Forgetting" by M. Boschini, L. Bonicelli, A. Porrello, G. Bellitto, M. Pennisi, S. Palazzo, C. Spampinato, and S. Calderara [arxiv][github] (main conference, poster),
"Dress Code: High-Resolution Multi-Category Virtual Try-On" by D. Morelli, M. Fincato, M. Cornia, F. Landi, F. Cesari, and R. Cucchiara [arxiv][github] (main conference, poster),
"Consistency-based Self-supervised Learning for Temporal Anomaly Localization" by A. Panariello, A. Porrello, S. Calderara, and R. Cucchiara [arxiv][github] (workshop)
to the European Conference on Computer Vision (ECCV) that will be held in Tel Aviv on 23th-27th October 2022.
· 27 Sep 2022

Il 30 settembre 2022, la Prof. Rita Cucchiara interverrà alla giornata di approfondimento "IL LAVORO NELL' ERA DELL' INTELLIGENZA ARTIFICIALE - IL RAPPORTO TRA TECNOLOGIE DIGITALI E QUALITA' DEL LAVORO PER UN PROGRESSO AL SERVIZIO DELLA SOCIETA'" che si terrà presso il Tecnopolo di Modena, dalle ore 14.30 alle 17.00.
L'iniziativa, di cui potete trovare qui il programma, si terrà nell'ambito delle giornate di Modena Smart Life Festival - Umanesimo 5.0. e vedrà la partecipazione di rappresentanti della tecnica, dell’economia, delle scienze aziendali e del diritto, mettendo a confronto esponenti del mondo accademico e della società civile.
Per motivi organizzativi, si chiede ai partecipanti la registrazione a questo link.
Prof. Rita Cucchiara's keynote speech at CLEF 2022 · 06 Sep 2022

We are proud to announce Prof. Cucchiara's keynote speech 'A journey into image captioning research' today at CLEF 2022 conference, hosted by Università di Bologna, Italy.
Building on the format first introduced in 2010, CLEF 2022 consists of an independent peer-reviewed conference on a broad range of issues in the fields of multilingual and multimodal information access evaluation, and a set of labs and workshops designed to test different aspects of mono and cross-language Information retrieval systems.
Keynote speech's slides available here
For more info on CLEF 2022, check the website
Best paper award at CBMI 2022 · 21 Jul 2022

Our paper:
Retrieval-Augmented Transformer for Image Captioning
Sara Sarto, Marcella Cornia, Lorenzo Baraldi and Rita Cucchiara
has been selected as best paper at the International Conference on Content-based Multimedia Indexing (CBMI 2022).
Abstract:
Image captioning models aim at connecting Vision and Language by providing natural language descriptions of input images. In the past few years, the task has been tackled by learning parametric models and proposing visual feature extraction advancements or by modeling better multi-modal connections. In this paper, we investigate the development of an image captioning approach with a kNN memory, with which knowledge can be retrieved from an external corpus to aid the generation process. Our architecture combines a knowledge retriever based on visual similarities, a differentiable encoder, and a kNN-augmented attention layer to predict tokens based on the past context and on text retrieved from the external memory. Experimental results, conducted on the COCO dataset, demonstrate that employing an explicit external memory can aid the generation process and increase caption quality. Our work opens up new avenues for improving image captioning models at larger scale.
Paper accepted at RA-L + IROS2022 · 30 Jun 2022

Our paper
"Semi-Perspective Decoupled Heatmaps for 3D Robot Pose Estimation from Depth Maps"
by A. Simoni, S. Pini, G. Borghi, and R. Vezzani [website, dataset]
has been accepted for publication in IEEE Robotics and Automation Letters (RA-L), and for presentation to IEEE/RSJ International Conference on Intelligent Robots and Systems, 23-27 October 2022, Kyoto (Japan).
Call for Phd @UNIMORE AIMAGELAB · 17 Jun 2022

The following Phd grants are available:
Call for International School in Information and Communication Technologies at UNIMORE, Modena, Italy
-
up to 2 grants on Artificial intelligence, Machine Learning and Computer Vision
-
1 grant on “Vision and Language integration”, funded by the PRIN CREATIVE project for generative learning for multimodal generation and understanding
-
1 grant on “Open Vocabulary Segmentation”, co-funded by Leonardo Spa
-
1 grant on “Digital Document Understanding and Natural Language Processing”, co-funded by Altilia Srl
-
1 grant on “AI Architectures for large-scale, explainable, image retrieval”, co-funded by Leonardo Spa
-
1 grant on “3D digitization of vehicles”, co-funded by Prometeia Spa
-
1 grant on “Novel deep Learning techniques under weakly and uncertain annotation in continuous and batch regime co-funded by Axyon AI
-
2 grants on "AI techniques for time series analysis and prediction exploiting structured information” co-funded by Ammagamma
-
1 open grant on novel architectures for human behavior tracking and understanding under batch and incremental training regime
-
1 grant on “AI in Fintech: Semi-supervised Learning for Transactional Time Series and Financial Data”, funded by Prometeia (only for internal employees)
-
1 open grant on “Causal representation learning and modular Artificial Intelligence for human action understanding”
Official call: https://www.unimore.it/AZdoc/CallPhDEnglishXXXVIIIWeb.pdf - closes in few weeks.
Call for Phd in the National School in Artificial Intelligence for Society (Course Cordinator University of Pisa, PhD at Aimagelab Unimore)
-
1 grant on “Medical Imaging: deep learning approaches for combining 3D volumes and whole slide images”.
-
1 open grant on "Causal representation learning and modular Artificial Intelligence for human action understanding”
The call will be open soon.
For any request, please write to segreteria.aimagelab@unimore.it.
'Machine Learning Applications in Trading and Portfolio Management' seminar - Prof. Petter Kolm · 07 Jun 2022

On Tuesday, June 7th at 3 p.m, Prof. Petter Kolm from the Courant Institute of Mathematical Sciences, New York University, will give an invited talk concerning 'Machine Learning applications in trading and Portfolio management'.
Over the course of the talk, an overview of some of the most recent Machine Learning applications in trading and portfolio management will be illustrated. Subsequently, the subject of ML applications in finance will be addressed, discussing at which point the research in this field is at the present moment, and in which direction it is auspicable for it to go.
The seminar is organized with the support of the company Axyon AI, as part of the “School in AI: Deep Learning, Vision and Language for Industry” of Emila Romagna ASAI. It will be held at Room P 0.4. (Building MO-25), via Pietro Vivarelli, 10/1 - Modena.
More info here
You can also attend the seminar online via Teams through this link
Seminar in the "Spotlights Seminars on AI" series · 30 May 2022

Prof. Cucchiara will give, within the "Spotlights Seminars on AI" series organized by the AIxIA, a seminar entitled "Human behavior understanding in large-scale visual data".
The seminar will be held on 30/5 at 17.00, and will be broadcast on the AIxIA Youtube channel (https://www.youtube.com/c/AIxIAit).
Further information is available in the seminar flyer: https://aixia.it/wp-content/uploads/2022/04/Seminar_Cucchiara.pdf
Best Student Paper Award sponsored by NVIDIA @ ICIAP 2021 · 27 May 2022

Our paper "Investigating Bidimensional Downsampling in Vision Transformer Models" by Paolo Bruno, Roberto Amoroso, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, and Rita Cucchiara has been selected for the Best Student Paper Award sponsored by NVIDIA at ICIAP 2021, which is being held in Lecce, Italy, from May 23rd to May 27th, 2022. In this paper, we investigated the application of a bidimensional max-pooling operator to improve the efficiency of Transformer-based architecture.
You can find the presentation here.
AIRI ad R2B - RESEARCH TO BUSINESS. Modena, 8 giugno 2022 · 24 May 2022

l'8 giugno 2022, AIRI, assieme al Dip. di Economia 'Marco Biagi' e al Dip. di Giurisprudenza di Unimore in collaborazione con il Tecnopolo di Modena, vi invita alla giornata di approfondimento sul presente e il futuro dell’Intelligenza Artificiale e sul ruolo dei Big Data nella trasformazione della società. Gli eventi si svolgeranno nell’ambito di R2B – Research to Business, la manifestazione punto di riferimento per il sistema regionale e nazionale dell’innovazione.
Due gli appuntamenti in programma:
Dalle ore 11.00 alle 12.00 presso Auditorium del Tecnopolo di Modena, Via Vivarelli, 2, Modena
'Sistemi intelligenti, robotica e medicina innovativa'. Qui il programma degli interventi.
Per iscriversi: https://bit.ly/R2B080622
Dalle ore 14.30 alle 18.30 presso Aula Magna del Dipartimento di Giurisprudenza, Via S.Geminiano 3, Modena
'Intelligenza Artificiale, Lavoro, Impresa tra applicazioni pratiche e regolazione europea' . Qui il programma degli interventi.
Per iscriversi: https://bit.ly/R2B080622
School in AI: Deep Learning, Vision and Language for Industry - second edition · 12 May 2022

After the first extremely successful edition in February, we are happy to announce the second edition of the “School in AI: Deep Learning, Vision and Language for Industry”, a new and intensive two-week training course at UNIMORE.
The second edition of the course will be held from 5th September 2022 to 16th September 2022, and is aimed at recent graduates in subjects where computer technology is now crucial, who do not yet have a specific training on Artificial Intelligence, and to all those who are already employed but want to keep up with the developments in the professional world. It consists of a first week of “foundational” and a second week of “strengthening” AI training, followed by a practical experience, developing a project with the support of the course tutors and possibly in collaboration with companies. Furthermore, seminars and detailed supplementary material will integrate the lessons.
The course is free for 30 graduated students and practitioners and entirely funded by the Emilia Romagna Region through the “Advanced Schools in Artificial Intelligence in Emilia-Romagna” project.
For more info on the second edition of the School in AI and how to apply, check the School website
Three-year project of high education in the cultural, economic and technological field pursuant to art. 2 of the regional law n. 25/2018 approved with resolution of the regional council n.1251/2019.
Expert.ai Platform: from vision to production · 26 Apr 2022

On Tuesday, April 26th, at 4:00 p.m., Alessandro Insabato (Expert.ai) will give an invited talk on "Expert.ai Platform: from vision to production".
Expert.ai is a leader in the field of Artificial Intelligence applied to the analysis of texts, with over 20 years of experience in understanding natural language. The presentation will cover their current research activities and their artificial intelligence platform based on a hybrid approach, supporting solutions able to solve problems related to the understanding of natural language.
The seminar is organized as part of the “School in AI: Deep Learning, Vision and Language for Industry” of Emila Romagna ASAI and part of the course "Computer Vision and Cognitive Systems".
The seminar will be held at Sala Eventi of Modena's Tecnopolo (via Pietro Vivarelli, 10/1 - Modena). More information can be found here: http://aiacademy.unimore.it/news/expertai-platform-from-vision-to-production
Dress Code Dataset · 21 Apr 2022

We are very happy to announce the release of Dress Code, the largest publicly available dataset for image-based virtual try-on.
Dress Code contains more than 50k high-resolution image pairs divided into three different categories (i.e. dresses, upper-body clothes, lower-body clothes). All images come from different catalogs of YOOX NET-A-PORTER.
More details about the dataset can be found in our paper:
"Dress Code: High-Resolution Multi-Category Virtual Try-On"
by D. Morelli, M. Fincato, M. Cornia, F. Landi, F. Cesari, R. Cucchiara [arXiv]
Dress Code is publicly available at: https://github.com/aimagelab/dress-code.
Webinar 'Prove tecniche di futuro' · 20 Apr 2022

Oggi alle ore 14:30 la Prof. Cucchiara interverrà al Webinar 'Prove tecniche di futuro', evento organizzato da Anitec-Assinform per discutere di talenti, ricerca ed adozione dell'AI in Italia.
Il webinar è aperto a tutti e si può seguire su questo link.
Scaletta e dettagli dell'evento consultabili qui
Prof. Cucchiara's invited talk at 'Make science and technology ready for the next challenges' conference · 11 Apr 2022

We are proud to announce prof. Cucchiara's intervention today at 12:30 at the 'Make science and technology ready for the next challenges' conference, organized by the Italian Embassy in Belgrade for the V Italian Research Day in the World.
Policy makers, programme managers and Italian and Serbian scientists to discuss the research policies that the two countries are developing to address the scientific, technological and social challenges of the coming years. The objective is to facilitate the comparison and sharing of the respective priorities, strategies and funding instruments, in order to assess the synergies between the national programmes and to strengthen bilateral scientific cooperation.
To follow the Zoom web stream, click here
'Research challenges in Leonardo Labs: applied Deep Learning in the Industry' seminar · 04 Apr 2022

On Wednesday, April 6, at 2:00 p.m., Alesandro Nicolosi (Principal Investigator of A.I. Research Area of Leonardo Labs) will give an invited talk on 'Research challenges in Leonardo Labs: applied Deep Learning in the Industry'.
The seminar is organized as part of the “School in AI: Deep Learning, Vision and Language for Industry” of Emila Romagna ASAI and part of the course "Computer Vision and Cognitive Systems". It will be held at Sala Eventi of Modena's Tecnopolo (via Pietro Vivarelli, 10/1 - Modena).
More info here
You can also attend the seminar online via Teams through this link
Papers Accepted at CVPR 2022 · 19 Mar 2022

Our papers:
"How many Observations are Enough? Knowledge Distillation for Trajectory Forecasting" by A. Monti, A. Porrello, S. Calderara, P. Coscia, L. Ballan, and R. Cucchiara [arXiv]
"Improving Segmentation of the Inferior Alveolar Nerve through Deep Label Propagation" by M. Cipriano, S. Allegretti, F. Bolelli, F. Pollastri, and C. Grana [website]
have been accepted to CVPR 2022, 19-24 June 2022, New Orleans (USA).
How Far Can Synthetic Data Take us? 7th Workshop on Benchmarking Multi-Target Tracking · 18 Mar 2022
In conjuction with the conference on Computer Vision and Pattern Recognition (CVPR) 2022, we are organizing the 7th Workshop on Benchmarking Multi-Target Tracking!
Synthetic data has the potential to enable the next generation of deep learning algorithms to thrive on unprecedented amounts of free labelled data while avoiding privacy and dataset bias concerns. As recently shown in our MOTSynth work, models trained on synthetic data can already achieve competitive performance when tested on real datasets.
At the 7th BMTT workshop, we aim to bring the tracking community together to further explore the potential of synthetic data. We have an exciting line-up of speakers, and are organizing two challenges aiming to advance the state-of-the-art in synthetic-to-real tracking.
Corso EUROCC "Intelligenza Artificiale per le industrie corso pratico: IA e Supercalcolo" · 08 Mar 2022

Sono aperte le iscrizioni al corso gratuito EUROCC: "Intelligenza Artificiale per le industrie corso pratico: IA e Supercalcolo", che si terrà a Modena in presenza presso gli spazi di FEM (Complesso Sant’Agostino, Largo Porta Sant’Agostino 228) in collaborazione con AImageLab e Ago Modena Fabbriche Culturali.
Il corso si terrà il 21, 22, 28 e 29 marzo 2022 dalle 9:00 alle 18:00.
Sarà suddiviso in due moduli, e avrà lo scopo di fornire una panoramica completa del mondo dell’Intelligenza Artificiale, strettamente legate alla tecnologia abilitante del supercalcolo (HPC). Il primo modulo sarà volto a fornire una panoramica generale sulle tecniche introduttive per l’utilizzo di una macchina HPC, fornendo un’introduzione agli algoritmi e alle tecniche base di Intelligenza Artificiale. Successivamente il corso si concentrerà sulle moderne tecniche di Intelligenza Artificiale utilizzate in ricerca e produzione, focalizzandosi sia sulla teoria alla base degli algoritmi sia su esempi pratici e concreti utilizzando l’HPC Marconi100 di CINECA.
Per maggiori informazioni e per iscriversi:
https://eventi.cineca.it/en/hpc/intelligenza-artificiale-lindustria/modena-20220321
Aimagelab is hiring: open positions for next Phd program · 25 Feb 2022
Aimagelab is hiring: open positions for the next PhD program:
1. Improving state-of-the-art Deep Learning solutions in Financial/Banking Time Series understanding, with generative learning (industrial Phd position)
2. Real time interactive and collaborative AI in Robotics (PhD position funded by industry)
3. Improving state-of-the-art Deep Learning solutions in NLP for Document Understanding (industrial Phd Position)
4. Visual and Language Generative AI (Phd position funded by MUR-PRIN)
in addition:
5. Research position (for graduate AI Engineer) for AI in Sailing data analysis (both Vision and sensing data)
Paper Accepted for publication on T-PAMI · 18 Jan 2022

Our paper:
"From Show to Tell: A Survey on Image Captioning"
by M. Stefanini, M. Cornia, L. Baraldi, S. Cascianelli, G. Fiameni and R. Cucchiara
has been accepted for publication on IEEE Transactions on Pattern Analysis and Machine Intelligence
HumanE-Ai-Net project: new video · 17 Jan 2022

School in AI: Deep Learning, Vision and Language for Industry · 21 Dec 2021

We are proud to announce the first edition of the School in AI: Deep Learning, Vision and Language for Industry.
This intesive two-weeks course will be held from 14th February 2022 to 25th February 2022, and is aimed at recent graduates in STEM subjects where computer technology is now crucial (medicine, economics, up to digital humanities), who do not yet have a specific training on Artificial Intelligence, and to all those who are already employed but want to keep up with the developments in the professional world.
The School is free and entirely financed by Regione Emilia Romagna, through the project “Advanced Schools in Artificial Intelligence in Emilia-Romagna”.
During the entire duration of the course, the synergy with the territory will provide interventions and company visits to integrate the school training with practical examples of application and workshops, to make what was introduced in the lessons concrete. Furthermore, seminars and detailed supplemertary material will integrate the lessons.
For more info on the AI School, check the website
Three-year project of high education in the cultural, economic and technological field pursuant to art. 2 of the regional law n. 25/2018 approved with resolution of the regional council n.1251/2019.
Prof. Rita Cucchiara's intervention at Credem's 'Data Heroes' event · 16 Dec 2021

We are proud to announce Prof. Rita Cucchiara’s intervention today at 16:00 CET at Credem's web event on 'Artificial Intelligence: challenges and opportunities': an evening dedicated to 4 'Data Heroes' that through their professionalism, skills and passions, inspire to explore the world of data with different views.
The interventions will revolve around what are the impacts of AI within our reality and how to integrate it into business processes in order to create value for the customers.
To follow the web stream, click the link below:
https://www.youtube.com/watch?v=tNPUWphF77A
Seminar 'DAT & Prometeia: innovation in the Automotive sector through reliable data and cutting-edge technologies' · 03 Dec 2021

On Friday, December 3rd, 2021 at 8:30 a.m., Helmut Eifert (Responsible Managing Director for DAT's group wide Innovation- and Product management and International business) and Fabio Fumarola (Principal AI Engineer Computer Vision and Machine Learning at Prometeia) will give an invited talk on 'DAT & Prometeia: innovation in the Automotive sector through reliable data and cutting-edge technologies'.
The event is organized as part of a cycle of seminars on AI for Automotive, as part of the "AI for Automotive" and "Learning Algorithms for Smart Intelligent Systems" courses (Prof. Cucchiara, Baraldi) and will be held in Aula P1.4, Building MO-25 (via Pietro Vivarelli, 10 - Modena).
More info at https://aimagelab.ing.unimore.it/imagelab/uploadedFiles/Seminario_3_Dicembre_INFO_0.pdf
Prof Rita Cucchiara's speech at 'Caffe Scienza' · 30 Nov 2021

Tonight at 7pm Professor Rita Cucchiara will speak at 'Caffè Scienza' (c/o Caffè Concerto, Piazza Grande, MO) on the theme 'Biometrics, Immune Apps and Faceapps: When Science Clashes with Ethics'
https://www.caffescienza.unimore.it/
(Online reservation is requested)
Prof Rita Cucchiara's keynote at Annual Data Driven Banking - ABI Milan, 26-28 October · 27 Oct 2021

Professor Rita Cucchiara spoke today at the seminar Annual Data Driven banking - ABI Milan: 3 days of analysis and interactive comparison with over 50 national and international speakers, to take stock of the current situation, analyze and share the lessons learned, scouting experiences and hypothesizing new experiments.
Keynote of Professor Cucchiara's intervention 'Artificial Intelligence: no longer an imitation game': Imitation_Game.pdf
ICCV 2021 · 13 Oct 2021

AImageLab is presenting one paper at ICCV 2021:
- "MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?"
by M Fabbri, G Brasó, G Maugeri, O Cetintas, R Gasparini, A Ošep, S Calderara, L Leal-Taixé, R Cucchiara
Q&A Time: Wednesday, October 13 at 13:00-14:00 (CEST) & Friday, October 15 at 00:22-00:23 (CEST)
Session: 8A & 8B
[paper] [video presentation]
Seminar from Prof. Marco Pavone · 12 Oct 2021

On Thursday, October 14th, 2021 at 5 p.m., Professor Marco Pavone (Stanford University, Director of Autonomous Vehicle Research at NVIDIA) will give an invited talk on "Safe, Interaction-Aware Decision Making and Control for Robot Autonomy". The event is organized as the fifth of a cycle of seminars on AI for Automotive, as part of the "AI for Automotive" and "Learning Algorithms for Smart Intelligent Systems" courses (Prof. Cucchiara, Baraldi) and will be streamed online.
Info and link to the streaming available HERE.
Virtual hearing on AI and transport - AIDA Committee · 11 Oct 2021

We are proud to announce Prof. Rita Cucchiara’s intervention today at 13.45-15.45 CET at European Parliament's Special Committee on Artificial Intelligence in a Digital Age (AIDA). The committee, together with the Committee on Transport and Tourism (TRAN), is organizing a virtual hearing on AI and Transport.
The hearing aims to explore how AI will transform the transport sector, looking at the impact of AI on transport modes and mobility until 2030, and discussing the EU transport policies and how to prepare for AI while minimizing risk.
To follow the web stream, click the link below:
https://multimedia.europarl.europa.eu/en/aida-tran_20211011-1345-COMMITTEE-AIDA-TRAN_vd
Matteo Fabbri vince il 1° Premio John McCarthy · 05 Jul 2021

Matteo Fabbri vince il premio di ricerca “John McCarthy” per ricercatrici e ricercatori under 35
Il Premio ha come obiettivo quello di valorizzare la conoscenza scientifica e favorire la visibilità di scienziati e ricercatori che, con la loro produzione, contribuiscono allo sviluppo e all’innovazione nel nostro paese. La sfida non è puramente tecnologica e riguarda il cambiamento del lavoro ed il fattore umano necessario per guidare e comunicare la trasformazione digitale e le nuove professionalità che si renderanno necessarie. Inoltre, il Premio si propone di incoraggiare l’impegno e l’attenzione dei protagonisti della ricerca nell’ambito dell’Intelligenza Artificiale.
Seminar · 21 Jun 2021

Dr. Iuri Frosio , PhD, NVIDIA USA
Seminar "Research in videogames: use of deep learning for saliency estimation and cheating prevention”
Abstract
working in a company that is a leader in both the videogames and machine learning fields offers exciting research opportunities at the intersection between these two domains. In this talk, I will illustrate two of these applications In the first part, I will concentrate my attention on saliency prediction in videogames, based on a dataset of Fortnite sequences that we acquired in 2019 I will illustrate the peculiar aspects of saliency in videogames, show that different frames in video sequences are not equally reliable, depending on the number of observers and frame content, and propose a general paradigm that explicitly takes this aspect into account when training a deep learning saliency prediction model. In the second part of the talk, I will introduce the problem of cheating in videogames and propose a deep learning based solution for the case of visual cheating Our method allows identifying cheaters with high probability, and it is designed to be robust with respect to potential adversarial attacks put in place by cheat designers I will conclude the talk by illustrating other potential research areas including videogames and deep learning.
The seminar will be held live from the Event Room of Technopole in Modena (Italy), street Vivarelli 2, 41125 (MO).
Wednesday 30th June, starting from 2pm.
Due to limited seating, REGISTRATION IS REQUIRED.
Those who can attend the seminar will receive an email the day before (June 29th).
The seminar will be broadcast in live streaming.
The full agenda and the link to the streaming are available on this page.
R2B ONAIR: R2B – RESEARCH TO BUSINESS DIGITAL EDITION · 15 Jun 2021

R2B ONAIR: R2B – RESEARCH TO BUSINESS DIGITAL EDITION
Alla vigilia della messa in campo di azioni senza precedenti come il Piano Nazionale di Ripresa e Resilienza e nuova Programmazione dei Fondi Europei 2021-2027, la nuova edizione di R2B OnAir guarda al futuro e alla ripartenza. Nei prossimi anni gli interventi e gli investimenti pubblici si concentreranno su alcuni grandi temi come transizione ecologica, big data, intelligenza artificiale e digitalizzazione, per generare il cambiamento di rotta richiesto a livello globale. Attraverso il contributo di relatori internazionali provenienti da istituzioni, enti di ricerca e imprese, R2B OnAir farà punto sullo stato di avanzamento della ricerca, sulle nuove tecnologie e sulle novità che, in questi ambiti, definiranno gli scenari futuri.
Gli appuntamenti di AIRI:
16 Giugno 2021, ore 12:00
I LABORATORI E LE COMPETENZE PER LE INDUSTRIE CULTURALI E CREATIVE
Digital library per la disseminazione del patrimonio culturale
Lorenzo Baraldi, Università degli Studi di Modena e Reggio Emilia
Luca Panini, Franco Cosimo Panini Editore
16 Giugno 2021, ore 14:00
AIRI – ARTIFICIAL INTELLIGENCE RESEARCH AND INNOVATION CENTER DEL TECNOPOLO DI MODENA
Durante il webinar verranno presentate alcune delle attività realizzate nel corso dell’ultimo anno in particolare in risposta alla call della Regione ER per la ricerca di soluzioni di contrasto alla diffusione del Covid-19 con due interventi a cura di Roberto Vezzani, Direttore AIRI – Artificial Intelligence Research and Innovation Center e Matteo Fabbri, Founder Go@AI e Assegnista PostDoc Università degli Studi di Modena e Reggio Emilia che illustrerà la tecnologia del distanziamento sociale Inter-Homines.
---> Programma e registrazione al link https://www.rdueb.it/
Civilian and Defence Applications of Artificial Intelligence, Big Data and High Performance Computing · 01 Jun 2021

Civilian and Defence Applications of Artificial Intelligence, Big Data and High Performance Computing
COVID pandemic has called for a faster transition towards the digitalization of services and data as key factor to manage societal needs, sustain economic growth, develop local communities, balance inequalities. The digital transformation is ignited by the creation and use of scientific hubs and infrastructures dedicated to Artificial Intelligence (AI), High Performance Computing (HPC) and Big Data. Digital infrastructures are developed by establishing key collaborations between public institutions and private enterprises.
Moreover, international collaborations are a key element for the effective development of such innovative and strategic initiatives. To this purpose, the Embassy of Italy, in collaboration with the Department of Science and Innovation and other relevant South African Departments and institutions, is organizing a two-day workshop (3-4 June 2021) to be held in Pretoria, (South Africa) and online.
Rita Cucchiara will contribute during the session dedicated to "AI for SMMEs growth and economic recovery", on 3rd June from 2.30 pm.
---> All the information and how to participate: https://bigdata.eventi.co.za/
Smarter Podcast, il podcast italiano sull'Intelligenza Artificiale · 19 May 2021

Smarter Podcast, il podcast italiano sull'Intelligenza Artificiale
Smarter è il podcast italiano sull'Intelligenza Artificiale (IA). Nel contesto di conversazioni live, esperti del settore provenienti dall'accademia o dall'industria vengono intervistati su diverse sfumature dell' IA e sull'impatto che queste hanno avuto e avranno sull'evoluzione del mondo in cui viviamo.
Rita Cucchiara sarà ospite del live che si terrà giovedì 20 Maggio alle ore 19:00.
Episodi disponibili sulle seguenti piattaforme:
• Youtube: shorturl.at/fsKZ1
• Spotify, Apple Podcasts, Google Podcasts: shorturl.at/hnxGR
Lo scienziato risponde: 'SCervelliamoCI - alla frontiera delle Neuroscienze' · 10 May 2021

Lo scienziato risponde: “SCervelliamoCI - alla frontiera delle Neuroscienze”
Una panoramica sulle sfide attuali delle neuroscienze
Moderati dal Dott. Andrea Gentile, gli ospiti si confronteranno sulle più recenti innovazioni in due campi d’avanguardia nel mondo delle neuroscienze: Neurogenomica e Intelligenza Artificiale. Rita Cucchiara tratterà il tema delle 'Nuove frontiere dell'Intelligenza Artificiale' analizzando vantaggi e criticità legati all'uso della nuove tecnologie di visione artificiale.
Lunedì 10 Maggio, 2021, ore 18:30
Live su:
https://www.facebook.com/EnableNetworkEU
https://www.youtube.com/watch?v=vJ3QOeSRQO4
Locandina disponibile QUI
Il Nuovo Regolamento Europeo sull'Intelligenza Artificiale · 05 May 2021

Il Nuovo Regolamento Europeo sull'Intelligenza Artificiale
Giovedì 6 Maggio si terrà l'evento promosso dall'Intergruppo Parlamentare sull’Intelligenza Artificiale guidato dal deputato Alessandro Fusacchia per una discussione sul nuovo regolamento europeo sull’AI.
L'evento online sarà trasmesso in streaming domani, Giovedì 6 Maggio 2021, dalle 16:15 alle 18:45 su Wired.it e sulla pagina Facebook di Wired.
Maggiori informazioni, programma completo e diretta streaming al link https://www.wired.it/attualita/tech/2021/05/04/intelligenza-artificiale-regolamento-europeo/
AI4Media Workshop on New Learning Paradigms & Distributed AI - Sustainable and privacy-preserving action understanding in Video · 04 May 2021

AI4Media Workshop on New Learning Paradigms & Distributed AI - 'Sustainable and privacy-preserving action understanding in Video'
On May 4th, AI4Media will organise an online workshop on “New Learning Paradigms & Distributed AI”, where the recent research advances achieved in the project on new learning paradigms will be presented. Specifically, the workshop will not only look into the new approaches going beyond the current achievements in deep learning (e.g., lifelong and continuous learning, moving beyond Variational Autoencoders (VAEs), manifold and transfer learning, neural architecture search, quantum-assisted learning, the fusion of evolutionary algorithms and deep learning), but also, the present solutions for decentralised and distributed computation.
The program includes specific presentations from the project partners and two invited presentations: Dr. Xavier Alameda-Pinedia (INRIA) and Prof. Rita Cucchiara (UNIMORE) who will talk about 'Sustainable and privacy-preserving action understanding in Video' (slide available HERE).
4 May 2021, from 08:55 to 13:10h
The full Agenda and how to participate are available HERE
Rita Cucchiara e Felice Cimatti: intelligenza, tra macchine e umani · 29 Apr 2021

Rita Cucchiara e Felice Cimatti: intelligenza, tra macchine e umani
L’Intelligenza Artificiale viene raccontata dalla voce di chi la sta progettando giorno per giorno nei centri di ricerca italiani: Rita Cucchiara in dialogo col conduttore Felice Cimatti spiega in che modo le macchine comprendono la realtà e la replicano, come si allena una rete neurale e quali sono le possibili applicazioni di questa nuova forma d'intelligenza.
Evento organizzato da AGO Fabbriche Culturali.
Giovedì 29 Aprile alle 18:00.
Diretta streaming alla pagina https://www.agomodena.it/it/livestreaming/
Digital Europe - Le parole per capire l'Europa · 28 Apr 2021

Digital Europe - Le parole per capire l'Europa
DIGITAL EUROPE
BIG DATA - Alberto Oddenino, UNITO
INTELLIGENZA ARTIFICIALE - Pastorale Universitaria, UNITO
ALGORITMI E SISTEMI - Rita Cucchiara, UNIMORE
In collegamento online, durante l'incontro parleranno alcuni massimi esperti per comprendere meglio il presente e futuro europeo: confini, guerra e pace, migrazioni, istituzioni e cittadini, no alle discriminazioni, digital europe. Per partecipare è necessario registrarsi. Incontro rivolto agli studenti delle scuole superiori.
Mercoledì, 28 Aprile, ore 12:00.
Maggiori informazioni: Locandina
Lorenzo Baraldi, Sara Tonelli | Manoscritti a macchina. Un progetto di comprensione automatica · 21 Apr 2021
Lorenzo Baraldi, Sara Tonelli | Manoscritti a macchina. Un progetto di comprensione automatica
Lorenzo Baraldi, Vicedirettore del Centro DHMoRe, sarà ospite di AGO Modena Fabbriche Culturali nell'ambito della rassegna iQuanti.
Tema del dialogo con Sara Tonelli - Fondazione Bruno Kessler è l'attività di ricerca che ha portato allo sviluppo e alla progettazione del nuovo prototipo di comprensione automatica dei manoscritti.
Mercoledì 21 Aprile 2021, ore 18:00
Segui lo streaming QUI
Radio3 Scienza - A.I. in E.U. · 19 Apr 2021

Radio3 Scienza - A.I. in E.U.
L'Unione Europea sta per avanzare una proposta di legge per regolamentare l'impiego dell'intelligenza artificiale. Quali rischi? Quali costi? Quali vantaggi? Qual è la terza via Europea dell'AI? Ne parlano Rita Cucchiara e Luciano Floridi in dialogo con Marco Motta durante il programma radiofonico Rai Radio 3 Scienza.
In diretta Lunedì 19 Aprile alle ore 11:30 al link https://www.raiplayradio.it/programmi/radio3scienza/
Ascolta la puntata al link https://www.raiplayradio.it/audio/2021/04/AI-in-EU-18bd7278-1e93-46b7-a9e0-20f57a5c4c66.html
Intersections - Conversation with Rita Cucchiara, Mark Dorf and Tamiko Thiel · 15 Apr 2021

GENERAZIONE CRITICA #7
STILL aLIVE
Intersections - Conversation with Rita Cucchiara, Mark Dorf and Tamiko Thiel
Intersections will be an opportunity to reflect with Professor Cucchiara, author of the volume “L'intelligenza non è artificiale. La rivoluzione tecnologica che sta già cambiando il mondo”, Mondadori, 2021, of the impact that new technologies have developed on our network of relationships and how their evolution has necessarily triggered a profound discussion in the ethical and philosophical field. The dialogue with international artists Mark Dorf and Tamiko Thiel will help to address the issue from the point of view of digital art, of contemporary digital artistic production, a broad and stimulating test field for technological experimentation.
For further information: https://www.generazionecritica.it/en/intersections-still-alive/
15th April 2021 – 5 pm
To join the event click HERE
Tech it NOW - COME COGLIERE LE OPPORTUNITA' DEL FUTURO · 15 Apr 2021

Tech it NOW - COME COGLIERE LE OPPORTUNITÀ DEL FUTURO
Con un inspire talk dal titolo 'Le sfide del 2021: tecnologia e società', Rita Cucchiara è ospite dell'evento di Vodafone Business dedicato ai manager e alle persone che, nelle aziende e nelle Pubbliche Amministrazioni, sono protagonisti della trasformazione digitale. Durante l’evento si parlerà delle sfide e delle opportunità offerte dall’innovazione, dell’impatto sulle comunità e sull’ambiente e delle tecnologie che accelerano il business.
Conduce e modera Emanuela Teruzzi Direttrice Responsabile di Inno3, con una grande esperienza legata agli scenari nell’ambito dell’innovazione digitale.
Giovedì 15 Aprile alle 9:15
Per consultare il programma ed iscriversi: https://vodafonetechitnow.it/
We are hiring! Open Research Positions @AImageLab · 13 Apr 2021

At AImageLab we have a few research fellow open positions for the period November 2021 - October 2024.
Please send your CV and your Motivation Letter to segreteria.aimagelab@unimore.it or rita.cucchiara@unimore.it.
The call will be available in May on the following topics:
1. Computer vision for fashion and Virtual try-on;
2. Computer vision for people tracking in traffic roads (with NVIDIA e CINECA);
3. Explainable AI with new self-attentive architectures;
4. Sustainable AI for training on HPC (with NVIDIA e CINECA);
5. AI in digital humanities for historical document recognition;
6. Human pose estimation in videos;
7. Human-computer interaction with depth and thermal cameras;
8. Medical Image Analysis: large images annotation (whole slide) with Deep Learning;
9. Medical Image Analysis: interfacing medical knowledge with machine learning systems with dedicated user interfaces;
10. Time series and structural data classification and forecasting with continual graph neural networks;
11. AI for future farming: Graph and geometric deep learning for 3D classification and re-identification of animals;
12. Unsupervised and semi-supervised continual learning for knowledge discovery and novelty detection in autonomous intelligent systems.
Session on AI and Robotics: Intelligent, Learning and Trustworthy Robots · 12 Apr 2021

ERF 2021 Session on AI and Robotics: Intelligent, Learning and Trustworthy Robots
On the 13th of April 2021, the Session on "AI and Robotics: Intelligent, Learning and Trustworthy Robots" will be held within the European Robotics Forum (ERF 2021). The workshop is organized by Andrea Orlandini, Alberto Finzi (Naples University), Marco Huber (IPA Fraunhofer) and Sotiris Makris (LMS Patras University).
Robotics is one of the most appealing and natural application area for the Artificial Intelligence (AI) research community. Advances in AI research in Robotics applications are fostering key enabling technologies such as, for instance, decisional and long term autonomy, learning, adaptability, interaction ability, dependability, and (more in general) cognitive abilities in Robotic platforms. Therefore, it seems essential for AI and Robotics research communities to respond to the challenges that these applications pose and contribute to the advance of intelligent robotics.
This workshop aims to provide an opportunity for researchers, innovators and industries communities to discuss current results in EU-funded projects, common interests and efforts, figure out shared challenges and discuss expectations about future developments in AI and Robotics.
Rita Cucchiara is going to give her highlight on the HumanE AI European Project through this PRESENTATION.
Registration available HERE
L'Intelligenza Artificiale nelle Smart Cities · 31 Mar 2021

Smart Italy! Città Sostenibili dopo il COVID-19
L’Intelligenza Artificiale nelle Smart Cities
Spunti di riflessione sui problemi e le possibili soluzioni per le città del futuro connesse all'AI, partendo dalle ricerche scientifiche e ipotizzando linee di indirizzo per le politiche e le strategie future.
La Prof. Rita Cucchiara è ospite di B4DS - Business Engineering for Data Science con una lectio magistralis oggi, 31 marzo 2021, ore 18:00.
---> Review the event here: https://www.youtube.com/watch?v=blm7tyHgYyc.
Explainable Artificial Intelligence on Computer Vision and Deep Learning · 30 Mar 2021

Explainable Artificial Intelligence on Computer Vision and Deep Learning
Ruifeng ZHU is a research fellow at AImageLab, received the M.S. from HIT in China between 2014 and 2016, Ph.D. from UBFC in France between Dec. 2016 and July 2020, dual Ph.D. UPV/EHU in Spain between Sep.2017 and July 2020. He has recently given a talk on his research activities on Explainable Artificial Intelligence on Computer Vision and Deep Learning. The talk has reviewed the current line of research on Explainable AI that Dr. Ruifeng ZHU and AImageLab are pursuing and developing.
ARTIFICIAL INTELLIGENCE FOR LIFE SCIENCES AND HEALTH TECHNOLOGIES · 24 Mar 2021

Italy-U.S. Webinar Series on Artificial Intelligence
ARTIFICIAL INTELLIGENCE FOR LIFE SCIENCES AND HEALTH TECHNOLOGIES
In order to connect the Italian communities in the US and in Italy, as well as to stimulate further collaborations in the AI domain, the Embassy of Italy and the Consular Network in the USA launched the "ITALY – US WEBINAR SERIES ON ARTIFICIAL INTELLIGENCE”, dedicated to AI applications to different aspects of society, everyday life and research.
The focus of the second event, jointly organized by the Embassy and the Consulate General in Boston, is “AI FOR LIFE SCIENCES AND HEALTH TECHNOLOGIES”.
The webinar will be opened by Armando Varricchio, Ambassador of Italy to the USA. Introductory remarks will be given by Henry Kautz, Director, Information & Intelligent Systems – NSF.
March 24th, 2021 12:00 PM in Eastern Time (US and Canada)
Webinar Registration HERE
Video di presentazione del Centro AIRI per il Clust-Er Innovate · 23 Mar 2021

Video di presentazione del Centro AIRI per il Clust-Er Innovate
Il Centro AIRI aderisce al Clust-ER Innovate della Regione Emilia-Romagna. Il Clust-ER Innovate è una associazione privata tra imprese, centri di ricerca, enti di formazione che condividono competenze, idee e risorse per sostenere la competitività del settore dell’innovazione nei servizi.
Il Responsabile Scientifico Prof. Rita Cucchiara racconta in una breve intervista perché il Centro AIRI è socio del Clust-ER Innovate e quali obiettivi ha sinora raggiunto.
Presentazione del libro 'L'intelligenza non è artificiale' · 16 Mar 2021

Presentazione del libro “L’intelligenza non è artificiale”
La Prof. Cucchiara è ospite dello SpazioF, mercoledì 17 Marzo, alle ore 17:00 per presentare la sua recente pubblicazione “L’intelligenza non è artificiale”, in dialogo con Sergio Gimelli della Fondazione di Modena. Il volume racconta la storia e l’evoluzione dell’Intelligenza artificiale dalla voce di chi la sta progettando giorno per giorno nei centri di ricerca italiani e spiega come essa sia frutto del pensiero, del controllo e del comportamento umano.
L’incontro sarà trasmesso in diretta streaming, a partire dalle ore 17, sul sito www.fondazionedimodena.it e sulla pagina Facebook della Fondazione.
Webinar 'Ethics in AI Seen and Thought by Women' · 09 Mar 2021

Webinar 'Ethics in AI Seen and Thought by Women'
Artificial Intelligence has been thriving for several years with an increase in the number of verticals using it. More than a tool, AI is becoming a new paradigm by redefining norms and pushing back the limits of human activity. To widely explore this topic, the conference puts forward two angles, being AI and social issues and AI governance in industry.
Prof. Rita Cucchiara is going to give her sight during the first panel named 'AI and societal issues' with Karine Gentelet (Université du Quebec en Outaouais), Valérie Bécaert (Service Now), Isabelle Herlin (Global Partnership on Artificial Intelligence (PMIA), and Nathalie Smuha (KU Leuveun).
The conference is organized by Ministère des Relations Internationales et de la Francophonie du Québec (MRIF).
---> March 10th, starting at 3 pm CET.
Free registration here: https://lnkd.in/d2m4KW3
Review the event here: https://www.youtube.com/watch?v=vs0-x3XgWtc
'L'intelligenza non è artificiale' · 07 Mar 2021

Presentazione del libro 'L'intelligenza non è artificiale', autore Prof. Rita Cucchiara
Domenica 7 Marzo alle ore 17:30 si terrà in streaming la presentazione del nuovo libro della Prof. Rita Cucchiara dal titolo 'L'intelligenza non è artificiale', La rivoluzione tecnologica che sta già cambiando il mondo, edito da Mondadori.
L'autore, ospite della rassegna 'Incontri con l'autore' del Forum Eventi, si racconta in dialogo con Federico Ferrazza, con la partecipazione di Martina Bagnoli.
Rivedi il live streaming: https://youtu.be/tEOJXM3o8n8
Per acquistare il libro: https://www.librimondadori.it/libri/lintelligenza-non-e-artificiale-rita-cucchiara/
Intervista Letture.org
INTELLIGENZA ARTIFICIALE, ROBOTICA E MACCHINE INTELLIGENTI: RICADUTE ETICHE E SOCIALI · 05 Mar 2021

Webinar INTELLIGENZA ARTIFICIALE, ROBOTICA E MACCHINE INTELLIGENTI: RICADUTE ETICHE E SOCIALI
Il convegno, promosso dall'Accademia Nazionale dei Lincei e Fondazione «Guido Donegani», si propone come una riflessione sui problemi riguardanti, in varia misura, l’occupazione, la riservatezza dei dati, la “privacy”, la violazione di valori etici e la fiducia nei risultati relativi all'Intelligenza Artificiale, alla Robotica e all'Automazione nella produzione industriale.
La Prof. Rita Cucchiara partecipa con un intervento dal titolo 'Deep learning nella visione e nel linguaggio'.
Venerdì 5 Marzo 2021, dalle ore 9:00.
I lavori potranno essere seguiti in streaming dal pubblico, il link comparirà il giorno stesso del Convegno al seguente indirizzo: https://www.lincei.it/it/live-streaming.
Il programma è disponibile QUI.
Webinar IL RUOLO DELLE INNOVAZIONI TECNOLOGICHE E DIGITALI · 25 Feb 2021

Webinar IL RUOLO DELLE INNOVAZIONI TECNOLOGICHE E DIGITALI
"Mobilità & Città: verso la post car city”
Il workshop online è organizzato nell'ambito della preparazione dell'Ottavo Rapporto Urban@it (https://www.urbanit.it/) dal titolo "Mobilità & Città: verso la post-car city" ed è orientato all'approfondimento del ruolo delle innovazioni tecnologiche e digitali. Il dibattito si concentrerà sulle implicazioni socio-economiche e spaziali della diffusione di innovazioni tecnologiche relativamente sia ai servizi di mobilità sia ai mezzi, come i mezzi a guida autonoma.
Venerdì 26 Febbraio 2021, dalle ore 16.30 alle ore 18.30.
Review the webinar HERE.
Meet the Researcher: Lorenzo Baraldi, Artificial Intelligence for Vision, Language and Embodied AI · 25 Feb 2021

Meet the Researcher: Lorenzo Baraldi, Artificial Intelligence for Vision, Language and Embodied AI
‘Meet the Researcher’ is a monthly series in which NVIDIA spotlights different researchers in academia who are using NVIDIA technologies to accelerate their work. This month the spotlight is on Lorenzo Baraldi, Assistant Professor at the University of Modena and Researcher at AImageLab.
Read the interview HERE.
The Intellectual Property metamorphosis in the Age of Digital Transition · 11 Feb 2021

The Intellectual Property metamorphosis in the Age of Digital Transition
High Level Conference Intellectual Property
February 11th, 2021, at 11:00 am CET, Prof. Rita Cucchiara will be part of the panel "INNOVATION IN THE PUBLIC AND PRIVATE SECTORS IN THE AGE OF DIGITAL TRANSFORMATION" with Luís Caldas de Oliveira from Instituto Superior Técnico (IST) and Ricardo Paes Mamede from University Institute of Lisbon (ISCTE).
The event is organized by the Portuguese Office of Industrial Property and the focus will be on the discussion and reflection on relevant matters directly related to Intellectual Property, regarding the need to hasten the digital transition as a driver for economic recovery, as well as promoting the digital transformation of businesses and the awareness that digital should be faced as a cluster of opportunities.
To register at the Conference please access the following link: https://hopin.com/events/european-union-intelectual-property-conference
ITALY-U.S. WEBINAR SERIES ON ARTIFICIAL INTELLIGENCE FOR FUTURE URBAN MOBILITY · 05 Feb 2021

Italy-U.S. Webinar Series on Artificial Intelligence
by Italian Consulate General of San Francisco
Italy and the USA have approved their National AI Strategy: the National Science Foundation, a major player and stakeholder in the AI field, as well as Italy’s historic partner, has recently launched the NSF-led National Artificial Intelligence Research Institutes; Italy has approved a pluriannual National Research Program, which is focused on AI and its applications and is planning to constitute a National Institute for Artificial Intelligence.
In order to connect the Italian communities in the US and in Italy, as well as to stimulate further collaborations in the AI domain, the Embassy of Italy and the Consular Network in the USA launched the "ITALY – US WEBINAR SERIES ON ARTIFICIAL INTELLIGENCE”, dedicated to AI applications to different aspects of society, everyday life and research.
The focus of this first event, jointly organized by the Embassy and the Consulate General in San Francisco, is “AI FOR FUTURE URBAN MOBILITY”. The webinar will be opened by Armando Varricchio, Ambassador of Italy to the USA. Introductory remarks will be given by Margaret Martonosi Assistant Director, NSF Computer Information Science and Engineering Directorate. The discussion will be carried out by an outstanding panel, composed by distinguished scientists, AI experts and entrepreneurs, representing US and Italian institutions.
Tuesday, February 9th, 2021, 10:00 PM CET
Flyer available HERE.
Paper Accepted for Publication on TPAMI · 26 Jan 2021

{kind=link}
Best Scientific Paper @ICPR 2020 · 18 Jan 2021
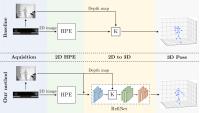
Our paper:
- RefiNet: 3D Human Pose Refinement with Depth Maps (D'Eusanio A, Pini S., Borghi G., Vezzani R., Cucchiara R.)
has been awarded as Best Scientific Paper at the 25th International Conference on Patter Recognition in the Biometrics track!
Click here to see the project's page.
Paper Presented at ICPR2020 · 15 Jan 2021

AImageLab presented the following papers at ICPR2020:
Explore and Explain:Self-supervised Navigation and Recounting
Roberto Bigazzi, Federico Landi, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara
A Novel Attention-based Aggregation Functionto Combine Vision and Language
Matteo Stefanini, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
VITON-GT: An Image-based VirtualTry-On Model with Geometric Transformations
Matteo Fincato, Federico Landi, Marcella Cornia, Fabio Cesari, Rita Cucchiara
Watch Your Strokes: Improving Handwritten Text Recognition with Deformable Convolutions
Iulian Cojocaru, Silvia Cascianelli, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara
RMS-Net: Regression and Masking for Soccer Event Spotting
Matteo Tomei, Lorenzo Baraldi, Simone Calderara, Simone Bronzin, Rita Cucchiara
RefiNet: 3D Human Pose Refinementwith Depth Maps
Andrea D'Eusanio, Stefano Pini, Guido Borghi, Roberto Vezzani, Rita Cucchiara
Anomaly Detection, Localizationand Classification for Railway Inspection
Riccardo Gasparini, Andrea D'Eusanio, Guido Borghi, Stefano Pini, Giuseppe Scaglione, Simone Calderara, Eugenio Fedeli, Rita Cucchiara
Future Urban Scenes Generationthrough Vehicles Synthesis
Alessandro Simoni, Luca Bergamini, Andrea Palazzi, Simone Calderara, Rita Cucchiara
DAG-Net: Double Attentive GraphNeural Network for Trajectory Forecasting
Alessio Monti, Alessia Bertugli, Simone Calderara, Rita Cucchiara
Confidence Calibration forDeep Renal Biopsy Immunofluorescence Images Classification
Federico Pollastri, Juan Maroñas, Federico Bolelli, Giulia Ligabue, Roberto Paredes, Riccardo Magistroni, Costantino Grana
A Heuristic-Based Decision Tree for Connected Components Labeling of 3D Volumes
Maximilian Söchting, Stefano Allegretti, Federico Bolelli, Costantino Grana
The DeepHealth Toolkit: aUnified Framework to Boost Biomedical Applications
Michele Cancilla, Laura Canalini, Federico Bolelli, Stefano Allegretti, Salvador Carrión, Roberto Paredes, Jon Ander Gómez, Simone Leo, Marco Enrico Piras, Luca Pireddu, Asaf Badouh, Santiago Marco-Sola, Lluc Alvarez, Miquel Moreto, Costantino Grana
Supporting Skin Lesion Diagnosis with Content-Based Image Retrieval
Stefano Allegretti, Federico Bolelli, Federico Pollastri, Sabrina Longhitano, Giovanni Pellacani, Costantino Grana
Rethinking Experience Replay: aBag of Tricks for Continual Learning
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Simone Calderara
The color outof space: learning self-supervised representations for Earth Observationimagery
Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Marco Cipriano, Pietro Fronte, Roberto Cuccu, Carla Ippoliti, Annamaria Conte, Simone Calderara
25TH INTERNATIONAL CONFERENCE ON PATTERN RECOGNITION FROM 10th TO 15th JANUARY 2021 · 10 Jan 2021

25TH INTERNATIONAL CONFERENCE ON PATTERN RECOGNITION from 10th to 15th JANUARY 2021
The 25th International Conference on Pattern Recognition, the main conference of the International Association on Pattern Recognition - IAPR that includes the areas of computer vision, image, sound, speech, sensor patterns processing and machine intelligence, will be held online from 10th to 15th January 2021.
The conference will address some of today most relevant topics as suggested by the declaratory "Putting Artificial Intelligence to work on patterns", and will present some of the best results in AI applied to pattern recognition in images and videos for robotics, medical analysis, documents, smart cities and society.
Despite the pandemic situation, the conference is the largest event ever in the history of ICPR:
- 1411 presentations of oral and poster papers,
- 56 countries presenting scientific works,
- 4 days of the main conference,
- 5 international keynotes,
- 27 demos, 8 competitions and 2 panels,
- 2 days for workshops and tutorials,
- More than 1800 already registered attendees (we expect a larger number given the free access to students from all over the world).
Useful links are available below:
- https://www.icpr2020.it/ the official ICPR2020 conference website
- https://www.underline.io/events/69/reception the UNDERLINE online platform (for conference participants)
- https://ailb-web.ing.unimore.it/icpr the ICPRBrowser similarity search of all papers is now available to everyone for one month.
Artificial Intelligence between Research and Industry · 07 Dec 2020

Artificial Intelligence between Research and Industry
On December, 7th from 7 pm the event 'Artificial Intelligence between Research and Industry' will be held by the Italian Institute of Culture, Consulate General of Italy, Italian Chamber of Commerce and Industry in UK, with the collaboration of the University of Glasgow.
Rita Cucchiara will join the panel chaired by Alessandro Vinciarelli, University of Glasgow, with other speakers who have successfully worked, in different roles, to make the dialogue between industry and academia successful: Stefan Raue (Arceptive), Olivia Gambelin (Ethical Intelligence), Marco Cristani (University of Verona), Vittorio Murino (University of Verona and Huawei), Alessio Del Bue (Italian Institute of Technology)
Info and streaming available HERE.
Seminar 'The use of artificial intelligence in the automotive industry: products and processes' · 30 Nov 2020

"The use of artificial intelligence in the automotive industry: products and processes", Eng. Marco Fainello
On December, 2nd at 8.30, Ing. Marco Fainello (Executive Director - Addfor S.p.a.) will give an invited talk on "The use of artificial intelligence in the automotive industry: products and processes". The event is organized as the fifth of a cycle of seminars on AI for Automotive, as part of the "Neural Network Computing, AI and Machine Learning for Automotive" and "Learning Algorithms for Smart Intelligent Systems" courses (Prof. Cucchiara, Baraldi) and will be streamed online.
Info and link to the streaming available HERE
Live Virtual Webinar Relatech X · 30 Nov 2020

Live Virtual Webinar Relatech X
On November, 30th from 4pm, Rita Cucchiara will attend an all-female discussion panel about the macro-themes of the so-called Digital Enabler Technologies, which guarantee the Digital Innovation and Transformation of companies, as a guest of Relatech.
Registration, program and streaming available HERE
Earth Observation and Artificial Intelligence for Global Health - AIDEO Project · 26 Nov 2020

Earth Observation and Artificial Intelligence for Global Health - AIDEO Project
Since 2020 AImageLab started a research project with the Science, Applications and Climate Department of Earth Observation Programme Directorate of ESA.
The project is part of a program which aims to indagate the spread of West Nile Virus (WNV), which is a mosquito-borne disease commonly transmitted to humans through the bite of an infected mosquito. The Earth Observation data obtainable through ESA’s Copernicus constellation is very helpful to understand if the ideal climatic and environmental conditions for mosquito population growth, and hence the spread of the virus, are present. Some key environmental variables (geographical, climatological and hydrological) that influence the transmission cycle of the virus can be monitored efficiently from satellites, which are capable of capturing these parameters frequently on a global scale.
Moreover, such environmental data can be integrated with Artificial Intelligence to create more reliable prediction models. The AIDEO project (“Artificial Intelligence and Earth Observation Data: innovative methods for monitoring West Nile Disease (WND) spread in Italy”) provides a model to predict where and when the WND could spread in Italy.
According to Simone Calderara, Professor at the AImageLab research group of the University of Modena and Reggio Emilia, Italy: “with AI and modern machine learning solutions it is possible to extract knowledge from the vast amount of data from Earth Observation missions and exploit the richness of weak correlations and recurrent patterns hidden inside. The unsupervised deep knowledge extraction module from AIDEO can be the cornerstone of several different applications that can benefit from the positive transfer of knowledge from the ESA Copernicus data stream”.
Read the full article: http://down2earth.esa.int/2020/11/earth-observation-and-artificial-intelligence-for-global-health/
Link to the Project
NVIDIA AI Technology Centre Italy "explained" · 26 Nov 2020

The webinar NVIDIA AI Technology Centre Italy "explained" was presented today at the presence of NVIDIA, CINECA and of the AIIS National Laboratory.
Matteo Tomei, a Ph.D. student of AImageLab, has presented his scientific work named "Towards Sustainable Video Modeling: Progressive Architecture Shrinkage for Action Recognition". The goal of the project, in collaboration with NVAITC and CINECA, is to train video-based deep networks with the help of HPC systems.
Full presentation available HERE.
III International Triple Helix Summit · 25 Nov 2020

III International Triple Helix Virtual Summit
At the III International Triple Helix Virtual Summit, 24-26 November 2020, leading figures from science, industry and politics will discuss the challenges posed by the COVID pandemic and other pressing grand challenges and how to address them via digital and sustainable innovation under the motto "Designing globally connected regional innovation ecosystems".
Prof. Rita Cucchiara will be on the stage during the panel "Quebec and Emilia-Romagna Triple Helix Dialogue to Empower Innovation Ecosystems through Big Data and Artificial Intelligence: the case of smart mobility", with Prof. Maurizio Sobrero (BBS University of Bologna), Marco Fainello (Engineer at Danisi Engineering, MASA), Prof. Dr. Remi Quirion (Chief Scientist of Quebec) and Prof. Emma Frejinger (Scientific Advisor, IVADO Labs).
Wednesday 25th November, from 5 pm.
Program and registration available HERE
"Deep Scene Perception without Labeled Data", Luigi Di Stefano · 24 Nov 2020

“Deep Scene Perception without Labeled Data”, Luigi Di Stefano
On November, 25th at 8:30, Prof. Luigi Di Stefano (University of Bologna) will give an invited talk on "Deep Scene Perception without Labeled Data". The event is organized as the fourth of a cycle of seminars on AI for Automotive.
For further information and to attend the seminar click here
Estense Digital Library. Nuovi strumenti per la consultazione, la ricerca e l’insegnamento. · 19 Nov 2020

Estense Digital Library. Nuovi strumenti per la consultazione, la ricerca e l’insegnamento.
A conference will be held on 20th November to discuss the prospects for the use of the Estense Digital Library's IIIF infrastructure (based on MLOL, Jarvis, Ariane platforms).
At 2:30 pm., Prof. Rita Cucchiara will give a keynote about "Intelligenza artificiale e il riconoscimento della scrittura manoscritta" in which the studies and the research hold on at AImageLab in the field of Cultural Heritage will be illustrated.
To attend the event: https://register.gotowebinar.com/register/8097843075825991693
Flyer of the event.
Presentation by Silvia Cascianelli and Rita Cucchiara
Seminar · 18 Nov 2020

Seminar "The 'auto' in 'auto'nomous, it is related to the co-pilot question"
On November, 19th at 9.00, Marc Proesmans (KU Leuven) will give an invited talk on "The 'auto' in 'auto'nomous, it is related to the co-pilot question". The event is organized as the third of a cycle of seminars on AI for Automotive, as part of the "Neural Network Computing, AI and Machine Learning for Automotive" and "Learning Algorithms for Smart Intelligent Systems" courses (Prof. Cucchiara, Baraldi) and will be streamed online.
Abstract
The race to develop a fully self-driving car has been going on for a while. The field of participants is diverse: from hip tech companies to major car manufacturers, some are more reckless than others. We give an insight in our research and development on autonomous cars, the technical challenges, the technologies we use, but with an eye on the needs from the industry, the end-users, the safety and comfort.
Link to the event: http://www.aiacademy.unimore.it/news/seminar-the-auto-in-autonomous-it-is-related-to-the-co-pilot-question
Canada-Italy Business Forum on Artificial Intelligence · 16 Nov 2020

Canada-Italy Business Forum on Artificial Intelligence
Following the success of the first edition of the Canada-Italy Business Forum on Artificial Intelligence - Ai, the Italian Chamber of Commerce in Canada - Iccc once again brings together Canadian and Italian AI stakeholders, universities, research centres, SMEs, start-ups and large companies, together with expert speakers and panelists during the second edition of the Business Forum held from 18 to 20 November 2020 in digital format.
The initiative, also promoted by the Emilia-Romagna Region, focuses on the artificial intelligence landscape in Italy and Québec, full of potential synergies and opportunities for collaborations, technology transfers and research projects.
Prof. Rita Cucchiara will focus on 'Italian strategy on AI' on 18th November at 3:00 pm during the Opening Conference.
Prof. Simone Calderara will present 'AI for learning humans through virtual worlds' on 19th November at 4:45 pm during the Digital Workshop - Industry 4.0.
➡ Details and Registration available here
Online Event · 08 Nov 2020

Vertigini scientifiche - Dal gene editing all’intelligenza artificiale
From 9th to 14th November Fondazione Umberto Veronesi (https://science.fondazioneveronesi.it/) will hold the XII edition of the Science for Peace and Health conference.
The theme of this year is "Vertigini scientifiche - Dal gene editing all’intelligenza artificiale". Prof. Rita Cucchiara will be a guest on the 9th November at 6:15 p.m. during the panel dedicated to Artificial Intelligence, Personal Freedom and Social Control.
➡ Review the event here
Seminar "Sportscar Vehicle Architecture: the starting point of conceiving a new car" · 05 Nov 2020

On November, 5th at 8:30, Ferrari S.p.A. will give an invited talk on "Sportscar Vehicle Architecture: the starting point of conceiving a new car". The event is organized as the second of a cycle of seminars on AI for Automotive, as part of the "Neural Network Computing, AI and Machine Learning for Automotive" and "Learning Algorithms for Smart Intelligent Systems" courses (Prof. Cucchiara, Baraldi) and will be streamed online and reserved to the students.
Educazione Intelligenza Artificiale · 02 Nov 2020

Educazione Intelligenza Artificiale - EDUIA 2020
Prof. Rita Cucchiara is going to present her vision about "Artificial Intelligence and machine learning for human empowerment" during the first day of the conference promoted by EDUIA and Roma Tre University, Department of Education Science.
The intention of the conference is to promote critical academic studies of the multiple scientific perspectives in the field of pedagogy, didactics, sociology, philosophy, engineering of information, computer science and other mathematical, social and humanistic sciences that focuses on observation, examine and critique of innovative technologies and their educational, ethical and social implications.
November, 5th at 10:45 a.m., follow the live streaming at http://www.eduia.it/eduia-2020/
Seminar "Autonomous Driving: the missing piece" · 26 Oct 2020

On October, 29th at 9.00, Alberto Broggi (VisLab srl) will give an invited talk on "Autonomous Driving: the missing piece". The event is organized as the first of a cycle of seminars on AI for Automotive, as part of the "Neural Network Computing, AI and Machihne Learning for Automotive" and "Learning Algorithms for Smart Intelligent Systems" courses (Prof. Cucchiara, Baraldi) and will be streamed online.
Abstract
Autonomous driving is currently a very hot topic, and the whole automotive industry is now working hard to transition from research to products. Deep learning and the progress of silicon technology are the main enabling factors that boosted the interest of industry and are currently pushing the automotive sector towards self-driving cars. Computer vision is one of the most important sensing technologies thanks to the extremely dense data set it can provide as output: object classification and recognition, precise localization, 3D reconstruction are just examples. This presentation addresses the missing piece that will allow future vehicles to make a full and efficient use of computer vision.
See the announcement on the AI Academy website for the link to the on-line streaming.
Rita Cucchiara at Eredità delle Donne Festival · 24 Oct 2020

EREDITÀ DELLE DONNE FESTIVAL
Scientists, economists, businesswomen, politicians, writers and artists confronted for three days on how to face the post-Covid-19 world: a "new" world, with its challenges, its suffering, its potential. This is Eredità delle Donne Festival.
Rita Cucchiara is going to give her vision on Saturday 24th at 5:20 pm in the panel Letters from the Future.
➡ Follow the Live streaming: https://ereditadelledonne.eu/
➡ Review the event: https://youtu.be/e27KitWYy8E
Intelligenza Artificiale, quale etica per il futuro. La via italiana ed europea all'innovazione. · 16 Oct 2020

Intelligenza Artificiale,
quale etica per il futuro.
La via italiana ed europea all'innovazione.
Lo stato dell’arte dell'AI, le sue applicazioni più promettenti, l’impatto su società, economia, politica e mondo del lavoro, la via italiana ed europea all’IA e la lotta alle malattie.
Questi sono solo alcuni dei grandi temi che verranno affrontati dalla Prof. Rita Cucchiara e da numerosi altri esponenti del mondo dell'innovazione digitale, guidati da Alessio Jacona, martedì 20 Ottobre, ore 15 in streaming su ANSA.it
➡ Review the event: https://vimeo.com/470089348
Paper Accepted for publication on T-PAMI · 14 Oct 2020
Our paper:
"Warp and Learn: Novel Views Generation for Vehicles and Other Objects"
by A.Palazzi, L.Bergamini, S.Calderara and R. Cucchiara
has been accepted for publication on IEEE Transactions on Pattern Analysis and Machine Intelligence
Paper accepted at NeurIPS 2020 · 13 Oct 2020

Our paper:
"Dark Experience for General Continual Learning: a Strong, Simple Baseline"
by P. Buzzega, M. Boschini, A. Porrello, D. Abati and S. Calderara
has been accepted (poster) at NeurIPS 2020, 6-12 December 2020, Vancouver, Canada.
'About Time' - Seminar by Prof. Arnold Smeulders · 25 Sep 2020

'About Time' - Seminar by Prof. Arnold Smeulders
Equivariant, temporal representations and networks are the topics that will be discussed during the seminar held by Prof. Arnold Smeulders, guest at the Tecnopolo of Modena.
Wednesday 30th September, 4:00 p.m.
Tecnopolo Event Room, 2, Vivarelli street, 41125 Modena
Modena Smart Life 2020 Intelligenza Artificiale, curiosità e immaginazione · 24 Sep 2020

Modena Smart Life 2020 Intelligenza Artificiale, curiosità e immaginazione
Il 25 Settembre dalle 11:00 alle 11:15 Rita Cucchiara e Lorenzo Baraldi saranno collegati il live streaming per parlare di IA e immaginazione in occasione del Modena Smart Life, il Festival della Cultura Digitale, giunto alla sua quinta edizione.
Consulta il link per maggiori informazioni:
https://www.modenasmartlife.it/2020/programma-25-settembre/intelligenza-artificiale-curiosita-e-immaginazione
MACHINE LEARNING E DEEP LEARNING - Corso teorico e pratico · 23 Sep 2020

Fondazione Democenter, in partenariato con la AI Academy del Dipartimento di Ingegneria Enzo Ferrari e il laboratorio di Ingegneria Informatica AImageLab ripropone una nuova edizione del corso in Machine Learning e Deep Learning con l’obiettivo di fornire a figure professionali con un background informatico competenze specialistiche aggiuntive per la progettazione e lo sviluppo di algoritmi di machine learning, per la raccolta, l’elaborazione, analisi di dati e l’identificazione di modelli.
Il corso, in accordo con i docenti, sarà erogato ON LINE in modalità sincrona (in diretta) prevedendo 2 sessioni di lezioni a settimana della durata ciascuna di 4 ore.
Per maggiori informazioni clicca qui.
Workshop - Towards European Sovereignty and Autonomy in AI · 17 Sep 2020

The European Research and Innovation Days is the European Commission’s annual flagship Research and Innovation event, bringing together policymakers, researchers, entrepreneurs and the public to debate and shape the future of research and innovation in Europe and beyond.
Prof. Rita Cucchiara is invited to discuss on how the different European initiatives will interact and boost their own resources to establish the basis for the European sovereignty and autonomy in AI in a special panel composed by Ioannis Kompatsiaris, Bernhard Schölkopf and Nuria Oliver, during the workshop named "Towards European Sovereignty and Autonomy in AI".
When? The 22nd of September, from 12:30 to 13:30
How to participate? Click here.
The full program is available here.
UNIMORE@ELLIS · 15 Sep 2020

We are proud to announce that AImageLab and the Interdepartmental Artificial Intelligence Research and Innovation Center of UNIMORE become part of the European network ELLIS!!!
The European Lab for Learning and Intelligent Systems (ELLIS) is an intergovernmental organization comprising 30 laboratories (ELLIS Units) in 14 European countries devoted to research on machine learning and intelligent systems.
Click here for more information.
Inter-Homines: Best Demo Award at ECCV 2020 · 01 Sep 2020

AimageLab won the Best Demo Award at ECCV 2020 with Inter-Homines.
Check the project page here for more information.
Open Research Positions @ AImageLab · 27 Jul 2020
At AImageLab we have three research fellow open positions on HPC, human understanding and generation for fashion data analysis.
Please send your CV at segreteria.aimagelab@unimore.it or rita.cucchiara@unimore.it.
AImageLab receives two ISCRA-C grants · 23 Jul 2020

AImageLab has received two ISCRA-C grants from NVIDIA, for accessing the supercomputing facilities of MARCONI100. MARCONI100 is the new accelerated not conventional Marconi partition, available from April 2020, and equipped with NVIDIA Volta V100GPUs.
Read more about the NVIDIA AI Technology Centre.
Workshop Human-centered Vision: from Body Analysis to Learning and Language · 07 Jul 2020
Giovedì 9 luglio 2020 - 15.00 - 17.00
PROGRAMMA:
15.00-15.10: benvenuto
15.10-15.30: introduzione ai Laboratori di Ricerca
- Biometric System Laboratory, Università di Bologna - campus di Cesena (Prof. Maltoni)
- AImageLab, Università di Modena e Reggio Emilia (Prof.ssa Cucchiara)
15.30 - 15.45: Real-Time Continual Learning from Natural Video Streams (Vincenzo Lomonaco e Lorenzo Pellegrini)
15.45 - 16.00: Classificazione Rehearsal-Based in Continual Learning. (Matteo Boschini, Pietro Buzzega e Simone Calderara)
16.00 - 16.15: People Behavior and Face Understanding (Roberto Vezzani, Stefano Pini, Matteo Fabbri e Fabio Lanzi)
16.15 - 16.30: The challenge of Morphing for border control (Matteo Ferrara e Annalisa Franco)
16.30 - 16.45: Modelli generativi per Image Translation e Continual Learning (Gabriele Graffieti)
16.45 - 17.00: Vision, Language and Action: from Captioning to Embodied AI (Lorenzo Baraldi, Federico Landi e Marcella Cornia)
AImageLab presenting three papers at CVPR 2020 · 17 Jun 2020

AImageLab is presenting three papers at CVPR 2020:
- "Compressed Volumetric Heatmaps for Multi-Person 3D Pose Estimation"
by M. Fabbri, F. Lanzi, S. Alletto, S. Calderara, R. Cucchiara
Date: Wednesday, June 17 & Thursday, June 18
Q&A Time: 12:00-14:00 and 00:00-02:00 (PST) / 21:00-23:00 and 09:00-11:00 (CEST)
Session: Poster 2.2 - Face, Gesture, and Body Pose; Motion and Tracking; Representation Learning
[paper] [code] [video presentation]
- "Conditional Channel Gated Networks for Task-aware Continual Learning"
by D. Abati, J. Tomczak, T. Blankevoort, S. Calderara, R. Cucchiara, B. E. Bejnordi
Date: Tuesday, June 16 & Wednesday, June 17
Q&A Time: 16:00-18:00 and 04:00-06:00 (PST) / 01:00-03:00 and 13:00-15:00 (CEST)
Session: Oral 1.4C - Transfer/Low-Shot/Semi/Unsupervised Learning
[paper] [oral presentation]
- "Meshed-Memory Transformer for Image Captioning"
by M. Cornia, M. Stefanini, L. Baraldi, R. Cucchiara
Date: Thursday, June 18 & Friday, June 19
Q&A Time: 09:00-11:00 and 21:00-23:00 (PST) / 18:00-20:00 and 06:00-08:00 (CEST)
Session: Poster 3.1 - Recognition (Detection, Categorization); Video Analysis and Understanding; Vision + Language
[paper] [code] [video presentation]
See the program for more.
Webinar Applicazioni dell'Intelligenza Artificiale nei settori industriali: le tecnologie Machine learning e Deep learning · 10 Jun 2020

Applicazioni dell’Intelligenza Artificiale nei settori industriali: le tecnologie Machine learning e Deep learning – 25 e 26 Giugno
Si terranno nelle giornate del 25 e 26 Giugno 2020 le due sessioni interattive di formazione previste nel corso “Applicazioni dell’Intelligenza Artificiale nei settori industriali: le tecnologie Machine learning e Deep learning”.
Democenter, in partnership con l'AI Academy di UNIMORE offre la possibilità di dare continuità ad iniziative formative sulla Intelligenza artificiale come parte integrante e fondamentale della trasformazione digitale delle imprese e lo fa proponendo le competenze presenti all’interno del laboratorio di ricerca AImageLab.
Il corso si propone di fornire a Operations Manager, R&D Manager, Responsabili IT, Responsabili delle varie aree aziendali una panoramica aggiornata delle applicazioni del Machine learning e Deep learning, delle problematiche relative a quali software e hardware adottare e quali sono i costi di tali soluzioni.
Relatore:
Ing. Simone Calderara, professore associato di Machine Learning e Deep Learning del Dipartimento di Ingegneria “Enzo Ferrari” dell’Università di Modena e Reggio Emilia, membro senior del laboratorio di computer vision, AI e Machine Learning AImageLab (direttore Prof. Rita Cucchiara) e membro senior dell’ AI Academy UNIMORE. Referente per UNIMORE nel laboratorio nazionale Artificial Intelligence and Intelligent System e nel gruppo di lavoro APRE Digital.
Tutte le informazioni e le modalità di partecipazione al seguente LINK.
Intervista a "Dialoghi sul nostro tempo" de L'Espresso · 29 May 2020

Una approfondita riflessione sulle potenzialità delle tecnologie che si basano sui sistemi di Intelligenza Artificiale, spaziando dalla panoramica sullo stato attuale della ricerca nazionale ed internazionale ad un approfondimento sull'AI a supporto della medicina. In che modo i sistemi intelligenti possono essere d'aiuto per fronteggiare gli inevitabili cambiamenti generati della pandemia da COVID-19? Quale contributo mette in campo l'AI? Cosa si prospetta nel prossimo futuro?
Ne parla la Prof. Rita Cucchiara, Responsabile di AImageLab e Direttore del LN AIIS del CINI, intervistata insieme a Roberto Cingolani, Head of Innovation in Leonardo-Finmeccanica ed ex Direttore Scientifico dell'IIT, da Marco Damilano durante la trasmissione Dialoghi sul Nostro Tempo de L'Espresso.
YNAP AI LAB@UNIMORE · 28 May 2020

As a leading company in the use of new technologies, Yoox Net-A-Porter Group, the most advanced fashion hub in Italy for Artificial Intelligence and Visual Recognition, has decided to join forces with the University of Modena and Reggio Emilia and has created a joint research program dedicated to Artificial Intelligence and Computer Vision in the field of fashion.
Press release available here.
NVAITC Webinar for the CINI community · 05 May 2020
To present the NVIDIA AI Nation program and the collaboration between NVIDIA AI Technology Center and the Italian research community, which has been launched in Modena last January, a webinar will be held on May 6th from 11:30 to 13:00. During the webinar, the Director of the CINI AIIS Lab, together with NVIDIA and CINECA will present the scope of the program and the computational resources available in Italy through CINECA.
Agenda of the webinar:
-
Introduction – Rita Cucchiara (UNIMORE)
-
NVAITC program, how to apply – Frederic Pariente, Giuseppe Fiameni (NVIDIA)
-
How to access CINECA resources – Marco Rorro (CINECA)
-
Q/A
Registration is available at the following link.
Galleria Estense of Modena: Walking through the museum, while staying home · 08 Apr 2020

The Galleria Estense of Modena, in partnership with AImageLab, organizes virtual tours that let visitors walk through the halls of the art gallery without leaving their homes.
In particular, connected users will be able to participate a virtual tour guided by a museum operator: these visits allow the continuation of the didactic proposal reserved to schools and the usual Sunday visits open to everyone. Both the activities were interrupted by the Covid-19 health emergency.
The 3D reconstruction of the Galleria Estense allows participants to move freely between the exhibition spaces and to communicate verbally with the guide, who can answer questions but also share analytical insights of the works and other documents related to the collections on display. This innovative experience in terms of involvement and cultural deepening is made possible thanks to Matterport technology.
The 3D acquisition of Galleria Estense was carried on by AImageLab as a part of a larger research project on Cultural Heritage and Digital Humanities supported by Fondazione di Modena.
We are proud that our work may now serve as a tool to promote education and culture in a time of emergency.
Press conference held by Martina Bagnoli and Rita Cucchiara:
Gazzetta di Modena
Modena in Diretta
Linked Researches:
Embodied Vision-and-Language Navigation
Self-Supervised Navigation and Recounting
Acquisition of 3D Environments for Robotic Navigation
High Skills for Research and Technological Transfer · 03 Apr 2020

Our research project "Automated detection of the Inferior Alveolar nerve Canal (IAC) in Cone Beam Computed Tomography (CBCT) using deep-learning techniques" has been selected by Emilia Romagna region in the call Alte Competenze per la Ricerca e il Trasferimento Tecnologico (High Skills for Research and Technological Transfer). Together with the research team of Prof. Alexandre Anesi, AImageLab will receive a 30,000.00 € grant for a research fellow position.
Accepted Paper at ICRA 2020 · 02 Mar 2020

The paper:
"SMArT: Training Shallow Memory-aware Transformers for Robotic Explainability"
by M. Cornia, L. Baraldi, R. Cucchiara
has been accepted to ICRA 2020, that will take place from May 31st to June 4th in Paris, France.
MORE AI - NVIDIA AI Nation, CINI ed UNIMORE · 07 Jan 2020
Il 16 gennaio dalle ore 14:30, presso il Tecnopolo di Modena, si terrà una giornata di presentazione dell'iniziativa "AI Nation NVIDIA" e del nascituro Laboratorio Congiunto NVAITC-UNIMORE (NVIDIA Artificial Intelligence Technology Center). L'evento è organizzato in collaborazione con il Laboratorio Nazionale CINI su Artificial Intelligence and Intelligent Systems (AIIS) e vedrà la partecipazione di UNIMORE, CINI, NVIDIA e aziende del territorio.
Il programma dell'evento e il link per la registrazione sono disponibili sul sito dell'AI Academy di Unimore.
Rita Cucchiara's keynote at the Georgetown University · 05 Nov 2019

Rita Cucchiara is giving an invited keynote on "Visual Intelligence: Research and Applications for Human-centered AI" at the Georgetown University in Washington, DC. The seminar is sponsored by the Georgetown University Italian Research Institute of Georgetown College, in collaboration with the Embassy of Italy, the Italian Cultural Institute, and the Georgetown University Center for Security and Emerging Technology.
Slides are available.
Abstract: Research and Applications for Human-centered AI Over the past decade, the joined research in Machine Learning and Computer Vision achieved impressive results worldwide, as of the most successful area of Artificial Intelligence. The capability of understanding images and video content reached new solutions both for autonomous intelligent systems and for an augmenting intelligence of human activities. The talk will focus on some aspects of what is called Visual Intelligence for AI-based systems, which mimics the typical human ability to understand the world, predict events, and imagine the possible through the visual perception. In particular, new research results for salient object recognition, attentional analysis and details detection in images will be presented, with reference of some projects carried out at AImagelab, in Italy, together with national and international companies. This visual intelligence capability is directly applicable in different contexts: the prediction of car-driver attention, the robot exploration of unknown environments, the detection of humans with their actions, the automatic description of image content by language as well as a novel way of knowledge extraction from cultural heritage data. Imagination, creativity, and curiosity-driven behaviour can be transferred to machines, now, and this will be potentially the core of future generations of human-centered AI.
Link to the event page
Paper accepted in Transactions on Image Processing · 30 Sep 2019
Our paper Spaghetti Labeling: Directed Acyclic Graphs for Block-Based Connected Components Labeling has been accepted in Transactions on Image Processing.
See the paper and the GitHub repository with the source code.
Abstract:
Connected Components Labeling is an essential step of many Image Processing and Computer Vision tasks. Since the first proposal of a labeling algorithm, which dates back to the sixties, many approaches have optimized the computational load needed to label an image. In particular, the use of decision forests and state prediction have recently appeared as valuable strategies to improve performance. However, due to the overhead of the manual construction of prediction states and the size of the resulting machine code, the application of these strategies has been restricted to small masks, thus ignoring the benefit of using a block-based approach. In this paper, we combine a block-based mask with state prediction and code compression: the resulting algorithm is modeled as a Directed Rooted Acyclic Graph with multiple entry points, which is automatically generated without manual intervention. When tested on synthetic and real datasets, in comparison with optimized implementations of state-of-the-art algorithms, the proposed approach shows superior performance, surpassing the results obtained by all compared approaches in all settings.
Best Paper Award at CAIP 2019 · 27 Sep 2019

Our paper How does Connected Components Labeling with Decision Trees perform on GPUs has been awarded as the best paper of the 18th International Conference on Computer Analysis of Images and Patterns.
See the paper and the GitHub repository with the source code.
In this paper the problem of Connected Components Labeling (CCL) in binary images using Graphic Processing Units (GPUs) is tackled by a different perspective. In the last decade, many novel algorithms have been released, specifically designed for GPUs. Because CCL literature concerning sequential algorithms is very rich, and includes many efficient solutions, designers of parallel algorithms were often inspired by techniques that had already proved successful in a sequential environment, such as the Union-Find paradigm for solving equivalences between provisional labels. However, the use of decision trees to minimize memory accesses, which is one of the main feature of the best performing sequential algorithms, was never taken into account when designing parallel CCL solutions. In fact, branches in the code tend to cause thread divergence, which usually leads to inefficiency. Anyway, this consideration does not necessarily apply to every possible scenario. Are we sure that the advantages of decision trees do not compensate for the cost of thread divergence? In order to answer this question, we chose three well-known sequential CCL algorithms, which employ decision trees as the cornerstone of their strategy, and we built a data-parallel version of each of them. Experimental tests on real case datasets show that, in most cases, these solutions outperform state-of-the-art algorithms, thus demonstrating the effectiveness of decision trees also in a parallel environment.
Third Place at the 2019 ISIC Challenge · 26 Sep 2019

Our research team, together with the PRHLT group from the Polytechnic University of Valencia, came third (out of 64 research groups) in the international competition on skin lesion classification (ISIC 2019).
See the online leaderboard.
Modena Smart Life 2019 · 24 Sep 2019

Human society and artificial intelligence: this is the subject of the 4th edition of Modena Smart Life, the Festival of digital culture located in Modena from 27th to 29th September 2019.
The technological evolution and the introduction of new intelligent systems and tools not only pervade communications, transports, robotics, medical and economic sectors but they suggest to investigate the ever closer human-machine interactions dynamics.
The activities set during the Festival of digital culture explore these aspects.
The UNIMORE AImageLab Professors are called to introduce their studies on the following matters:
-
Artificial and human intelligence: the engine of business Conference by CNA with Simone Calderara
-
Artificial intelligence vs humans Lectio Magistralis by Rita Cucchiara
-
The technological frontier: at what point are we? Keynotes by S. Calderara, L. Baraldi
-
ARTIficio: Artificial Intelligence meets Art Performative Installation by Rita Cucchiara, Massimiliano Corsini, Lorenzo Baraldi and Marcella Cornia
-
How the AI see human and his behaviour Keynote by R. Cucchiara
-
Robot doctor or doctor robot? Artificial Intelligence in medical sector Federico Cabitza in a dialogue with Simone Calderara
PersonArt - Who is your double? · 14 Sep 2019

PersonArt is an interactive system based on Artificial Intelligence that lets you find similarities between real faces and artistic images. The visitor is involved in a course that allows his/her to discover his/her own kind among the portraits of the Galleria Estense di Modena, starting an original and engaging tour. Behind the outcome there are some algorithms based on Deep Neural Networks aiming to identify the face and to extract its salient features in order to calculate similarities between visitor’s face and those on display into the Galleria.

Moreover, PersonArt uses artistic technique in order to decrease the domain gap between photos and artistic pictures, guaranteeing an accurate result transcending the differencesces of texture. The results are elaborated remotely by the high performance server at the seat of the Lab. in the Engineering Department.


Marcella Cornia e Lorenzo Baraldi have introduced these techniques in the most important international meeting in Artificial Vision (CVPR).
You can find the photo box in The Galleria Estense, fourth floor, Largo Porta Sant'Agostino, 337,41121 Modena (MO) Italia during the FestivalFilosofia (13 14 15 September 2019) and Modena Smart Life event (27 28 29 September 2019).

…Who is your double?
LAMV is being used at Facebook to detect harmful content · 03 Aug 2019

A solution for matching and detecting copied videos, developed by AImageLab and Facebook AI Research, is now being used in production scale at Facebook to detect harmful content.
Known as LAMV or TMK (Temporal Matching Kernel), this video-matching technology has been developed by research scientists at Facebook AI Research and by L. Baraldi and R. Cucchiara as part of a collaboration between AImageLab and FAIR. The algorithm is capable of producing a compact and temporal-aware signature of a video, which can be used for video copy detection and video retrieval. The solution combines match kernels, Fourier Transforms and end-to-end learning.
See the official announcement on the Facebook newsroom website, and the Github repository with the source code.
You can also read more details about this research activity on our website and read the CVPR 2018 paper.
Accepted Oral at BMVC 2019 · 05 Jul 2019

The paper:
"Embodied Vision-and-Language Navigation with Dynamic Convolutional Filters"
by F. Landi, L. Baraldi, M. Corsini, R. Cucchiara
has been accepted as oral to BMVC 2019, that will take place from September 9th to 12th in Cardiff, UK. The preprint is available.
Seminar announcement · 01 Jul 2019

On July, 15th at 11.00, Iuri Frosio (NVIDIA) will give an invited talk on "Computational Aspects of Deep Reinforcement Learning". The event will be hosted in the Auditorium of the Modena Technopole.
Abstract Deep reinforcement learning has recently emerged as a viable solution for many complex, real world problems. Nonetheless, the development of new deep reinforcement learning algorithms is still badly affected by the numerous instabilities and the long experiment turnaround time. In this talk I will first show how A3C, a standard deep reinforcement learning algorithm, can be accelerated through the adoption of a GPU for inference and training. I will also show that the limited CPU capability for the simulation of a large number of parallel environments as well as the limited CPU-GPU communication bandwidth constitute two significant bottlenecks in this approach. I will finally illustrate our CUDA Learning Environment (CuLE), which allows emulating thousands of Atari games in parallel on the GPU, removing the previously mentioned bottlenecks and opening the door to effective multi-GPU deep reinforcement learning. I will also illustrate few algorithm optimizations that are needed to leverage at best the large amount of data generated by CuLE.
Speaker Bio Iuri Frosio (http://research.nvidia.com/person/iuri-frosio) got his PhD in biomedical engineering at the Politecnico of Milan in 2006. He worked as research fellow at the Computer Science Department of the University of Milan from 2003 and an assistant professor in the same department from 2006 to 2013. In the same period, he worked as a consultant for various companies in Italy and in the US. He joined NVIDIA in 2014 as senior research scientist. His research interests include image processing, computer vision, robotics, parallel programming, machine learning, and reinforcement learning.
AImageLab hosts the first NVIDIA Inception Day in Italy · 24 Jun 2019

On July 8th, NVIDIA Inception and AImageLab are teaming up to organize a meetup for Machine and Deep Learning startups in Modena. The objectives of the event are to present NVIDIA platform solutions for ML/DL, let program members showcase their technology/products and network with their peers, as well as NVIDIA and AImageLab teams.
The meetup will feature advanced Inception members offering deep dives into their DL solutions, a pitching session with a Titan RTX GPU as the prize, a demo running on NVIDIA's DGX supercomputer and an informal networking session.
Obtaining a registration ticket is strongly encouraged. The registration page can be found at this link.
See also the event page on the AI Academy website.
Show, Control and Tell presented at the Workshop on Language and Vision · 16 Jun 2019
Our Show, Control and Tell model, accepted at CVPR 2019, has been presented as an invited oral at the Workshop on Language and Vision at CVPR.
Slides from the talk are available, as well as the paper from the main conference and the Github repo with datasets, code and pre-trained models.
Deep Learning for Computer Vision Applications · 23 May 2019

Lorenzo Baraldi, Guido Borghi e Marcella Cornia will give an invited talk at the Department of Information Engineering, Università Politecnica delle Marche.
For further information plase visit the website.
Best Paper Award @ U3DRM 2019 · 13 May 2019

The paper SEMANTIC SEGMENTATION OF BENTHIC COMMUNITIES FROM ORTHO-MOSAIC MAPS - G. Pavoni, M. Corsini, M. Callieri, M. Palma, and R. Scopigno presented at the 2nd International Conference on "Underwater 3D Recording and Modelling - A Tool for Modern Applications and CH Recording" (ISPRS Archives - Volume XLII-2/W10), has been considered among the best papers at the conference.
Conferenza stampa di presentazione della AI Academy · 13 May 2019

Modena e l'Università degli Studi di Modena e Reggio Emilia nei prossimi mesi si andranno a caratterizzare come uno dei più importanti centri di ricerca sull'Intelligenza Artificiale (AI) a livello italiano ed internazionale. Grazie ad una serie di significativi finanziamenti giunti dalla Regione Emilia Romagna, dalla Fondazione Cassa di Risparmio di Modena, cui si aggiunge un finanziamento del Ministero dell'Istruzione, dell'Università e della Ricerca su un progetto relativo alle capacità predittive delle reti neurali, nei prossimi mesi prenderà corpo la nascita di una AI Academy, che potrà disporre di una nuova ala in continuità con l'edificio del Tecnopolo di Modena.
Obiettivi, finalità e costruzione di questo Centro di Ricerca internazionale in Visione ed Intelligenza Artificiale e della AI Academy saranno illustrati in una conferenza stampa convocata per martedì 14 maggio alle ore 11.30.
Maggiori dettagli sono disponibili sul sito web dell'AI Academy.
Talk on Probabilistic Models by Juan Maronas · 09 May 2019

Juan, a PhD student from the PRHLT Research Center of the Universitat Politècnica de València will present his research on Probabilistic Models and their Calibration.
Three papers accepted at CVPR 2019 · 28 Feb 2019

AImageLab will present three papers at CVPR 2019:
Art2Real: Unfolding the Reality of Artworks via Semantically-Aware Image-to-Image Translation (M. Tomei, M. Cornia, L. Baraldi, R. Cucchiara)
Latent Space Autoregression for Novelty Detection (D. Abati, A. Porrello, S. Calderara, R. Cucchiara)
Show, Control and Tell: A Framework for Generating Grounded and Controllable Captions (M. Cornia, L. Baraldi, R. Cucchiara)
Invited talk at the "AI and Future Society" workshop at the British Embassy · 21 Feb 2019

As Director of the CINI Laboratory in "Artificial Intelligence and Intelligent Systems", Rita Cucchiara is giving an invited talk at the "AI and Future Society" workshop at Villa Wolkonsky in Rome. Slides are available.
Intelligenza Artificiale e Sicurezza Stradale: AImagelab premiato nuovamente a livello nazionale · 20 Feb 2019

La tesi magistrale intitolata "Studio e sperimentazione di sistemi di visione artificiale per il monitoraggio del conducente", sviluppata all'interno del laboratorio AImageLab, ha vinto il premio nazionale ANIA come migliore lavoro dell'area tecnico-ingegneristica riguardante il tema della sicurezza stradale, bissando il risultato del 2017.
Autore della tesi è Elia Frigieri, relatore la Prof.ssa Rita Cucchiara, correlatori il Prof. Roberto Vezzani e il dott. Guido Borghi.
La tesi si inserisce nel più ampio settore di ricerca riguardante l'utilizzo di algoritmi di Visione Artificiale e Deep Learning per il monitoraggio automatico del livello di attenzione del conducente durante l'attività di guida.
Link alla notizia pubblicata dalla Fondazione Ania
Clicca qui per maggiori informazioni riguardo al progetto di ricerca
We are glad to announce that the Master's Thesis "Studio e sperimentazione di sistemi di visione artificiale per il monitoraggio del conducente" developed at AImageLab by Elia Frigieri, Rita Cucchiara, Roberto Vezzani and Guido Borghi has won the national contest about Road Security, promoted by ANIA Foundation.
News link (from the ANIA web site)
Click here for more info about the research project
Convegno di presentazione dei risultati del Progetto di Ricerca e Innovazione - La Città Educante · 16 Jan 2019

A Roma, il 23 gennaio 2019 dalle ore 9.30 presso CNR, Sala Convegni in via dei Marrucini snc, si terrà il Convegno di presentazione dei risultati del Progetto di Ricerca e Innovazione
"La Città Educante". Per partecipare è necessario registrarsi a questo link: http://cittaeducante.azurewebsites.net/
Accepted Paper for PAMI Journal · 05 Dec 2018

The paper:
"Face-from-Depth for Head Pose Estimation on Depth Images"
by G. Borghi, M. Fabbri, R. Vezzani, S. Calderara, R. Cucchiara
has been accepted to be published in TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (TPAMI) journal.
Click here to read the preprint paper and here for further details.
Invited talk at MBDA · 13 Nov 2018

Rita Cucchiara gave an invited talk, "Artificial intelligence and Industry 4.0 a disruptive and necessary pair?", at MBDA.
Slides from the talk are available.
New Patenting Process at AImagelab · 31 Oct 2018

AImagelab is currently patenting an "Authentication System for Low-Light-Level Environments", in collaboration with the University of Modena and Reggio Emilia.
Inventors: Guido Borghi, Stefano Pini, Filippo Grazioli, Roberto Vezzani, Rita Cucchiara
Priority Number: 102018000008237
Keywords: Face Identification, Biometric Identification, Depth Maps, Infrared Sensors
For a brief description and images please visit the project page.
Invited talk at IROS 2018 · 04 Oct 2018

Rita Cucchiara gave an invited talk, "Computer Vision, AI and Robotics for Visual Intelligence", at the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2018, which was held in Madrid on October 1-5.
Slides from talk are available.
Terzo incontro all’Università sulla visione industriale · 26 Sep 2018
AImageLab ospiterà il “Terzo incontro all’Università sulla visione industriale”, organizzato da Editoriale Delfino Srl.
L’incontro si terrà Giovedì 4 Ottobre 2018 presso il Dipartimento di Ingegneria Enzo Ferrari, dalle 9 alle 13, presso la sala Eventi del Tecnopolo, edificio 52.
A chi si rivolge l’evento
Agli studenti delle lauree triennali e magistrali in Ingegneria, per mettere in contatto i futuri ingegneri con i fornitori di una tecnologia, quella dei sistemi di visione, che avrà sempre di più impiego nella produzione industriale. Dopo le presentazioni delle aziende intervenute, l’incontro prevede ampio spazio per un dibattito con gli studenti. L’evento è comunque aperto a chiunque volesse partecipare. Si richiede la registrazione mediante i link in calce.
Il Progetto Visione Industria è dedicato ai sistemi di visione industriali
Intende ricostruirne la storia, offrire materiale di documentazione, proporre supporti per la formazione, segnalare e mettere in collegamento i principali attori in campo industriale, nella ricerca e nei diversi enti e organizzazioni. Si rivolge a tutti coloro che si occupano, a vari livelli, di organizzazione, di gestione e di analisi dei processi produttivi, ai costruttori di macchine e impianti, ai responsabili della qualità, della logistica e della manutenzione ma anche a ricercatori, studenti, operatori della comunicazione. Il progetto, avviato col sostegno di aziende di primo piano del settore e col supporto di un qualificato Comitato Scientifico, verrà via via integrato e periodicamente aggiornato seguendo gli sviluppi tecnologici e di mercato del settore nei prossimi anni.
Link per iscriversi all’evento (GRATUITO): https://www.eventbrite.it/e/biglietti-terzo-incontro-la-visione-industriale-incontra-gli-ingegneri-nelle-universita-47662062512
Per gli studenti:
AImageLab Presentations @ ECCV 2018 Workshops · 08 Sep 2018

Slides of our presentations at ECCV 2018 Workshops are available.
"What was Monet seeing while painting? Translating artworks to photo-realistic images"
by M. Tomei, L. Baraldi, M. Cornia, R. Cucchiara
Oral presentation @ Workshop on Computer VISion for ART Analysis
"Visual-semantic alignment across domains using a semi-supervised approach"
by A. Carraggi, M. Cornia, L. Baraldi, R. Cucchiara
Spotlight presentation @ Multimodal Learning and Applications Workshop
Rita Cucchiara's keynote for the Maria Petrou Prize @ ICPR 2018 · 26 Aug 2018

Prof. Rita Cucchiara has been awarded the Maria Petrou Prize at ICPR 2018, held this year in Beijing.
Her keynote talk, entitled "The space, the time and the people: a journey in Re-id, Tracking and Detection", is available.
Accepted Paper at BMVC 2018 · 09 Aug 2018

The paper:
"Face Verification from Depth using Privileged Information"
by G. Borghi, S. Pini, F. Grazioli, R. Vezzani, R. Cucchiara
has been accepted to BMVC 2018, that will take place from September 3rd to 6th in Newcastle, England.
Accepted Paper at ECCV 2018 · 08 Aug 2018
The paper:
"Learning to Detect and Track Visible and Occluded Body Joints in a Virtual World"
by M. Fabbri, F. Lanzi, S. Calderara, A. Palazzi, R. Vezzani and R. Cucchiara
has been accepted to ECCV 2018, that will take place from September 8th to 14th in Munich, Germany.
People Tracking by their Pose: the JTA Dataset · 22 Jun 2018

Rita Cucchiara gave an invited talk, "People Tracking by their Pose: the JTA Dataset", at CVPR 2018, which was held at the Calvin L. Rampton Salt Palace Convention Center the week of June 18-22, 2018 in Salt Lake City, Utah.
JUMP – Evento finale · 31 May 2018

Evento Finale del progetto JUMP. 6 giugno 2018 – dalle ore 16:00 alle ore 19:30
Tecnopolo di Reggio Emilia – Piazzale Europa, 1 – Reggio Emilia
L’evento è gratuito. Programma della giornata
Per motivi organizzativi è richiesta l’iscrizione al seguente link.
Seminar by Prof. Pascal Fua · 23 May 2018

"Geodesic Convolutional Shape Optimization", Prof. Pascal Fua, Computer Vision Laboratory – EPFL
Lunedì 28 Maggio 2018, ore 14.45 -16.00, Sala Riunioni Primo Piano, Edificio MO52
International Workshop on Computer Vision · 02 May 2018

The International Workshop on Computer Vision will consist of high-quality invited talks by distinguished speakers, panels and discussions about emerging themes in computer vision and related fields. The main goal is to encourage people to talk about work in progress, so there will be no published proceedings. The sixth edition of IWCV will be held in Modena in Canalgrande Hotel, Italy, from the 29th to 31st of May 2018.
Seminar by Univ. of Ferrara - Città educante · 19 Apr 2018
During the final meeting of the partnership between Aimagelab and University of Ferrara within the Città Educante project, Profs Evelina Lamma, Fabrizio Riguzzi and Riccardo Zese hold a seminar about Symbolic Learning an Logic programming. The slides of the seminar are available for downloading (Slide1, Slide2).
Invited talk "L'arte dell'innovazione" · 21 Mar 2018

Rita Cucchiara gave an invited talk at "L'arte dell'innovazione", which was held in Modena on the 21st of March:
"L'intelligenza artificiale è (e) arte"
Slides from the talk are available.
Sensors - Special Issue on Depth Sensors and 3D Vision · 06 Mar 2018

We are organising a Special Issue entitled "Depth Sensors and 3D Vision" on Sensors and we would like to invite you to contribute one article/review to this special issue. Deadline for manuscript submissions: 31 August 2018.
For further reading, please follow the link to the Special Issue Website at:
http://www.mdpi.com/journal/sensors/special_issues/Depth_Sensors_3D_Vision
Invited talk at the "Technological Innovation for Digital Humanities" workshop · 06 Mar 2018

Lorenzo Baraldi gave an invited talk at the "Technological Innovation for Digital Humanities" workshop, held in Pavia on the 6th of March.
"CultMedia: Deep Learning for automatic description of images and video in DH"
Slides from the talk are available.
Invited talk at AI DIVE 2018 · 27 Feb 2018

Rita Cucchiara gave an invited talk at AI DIVE 2018, which was held in Milan on the 27th of February:
"Computer Vision and Deep Learning: and they lived happily ever after"
Slides from the talk are available.
CVPR 2018 · 20 Feb 2018

The paper:
"LAMV: Learning to align and match videos with kernelized temporal layers"
by L. Baraldi, M. Douze, R. Cucchiara and H. Jégou
has been accepted to CVPR 2018, that will take place from June 18th to June 22nd in Salt Lake City, Utah.
Why is Deep Learning so cool? · 11 Jan 2018

Il 29 gennaio 2018, presso la Sala Eventi del Tecnopolo di Modena si terrà l'evento:
"Why is Deep Learning so cool?"
Giornata dell'Associazione Italiana per la ricerca in Computer Vision, Pattern Recognition e Machine Learning, GIRPR → VPL
che ospiterà un talk del Prof. Naftali Tishby, Hebrew University of Jerusalem, e l'assemblea straordinaria dell'Associazione.
Ulteriori informazioni sono disponibili alla pagina dedicata all'evento.
Seminar by Dr. Hamed R. Tavakoli · 12 Dec 2017

Dr. Hamed Rezazadegan Tavakoli, Postdoctoral Researcher at Aalto University (Finldand) will give a talk about his research activities on Tuedsay, 12 at 17 pm. The talk will take place in the meeting room of building MO-52.
Dr. Hamed R. Tavakoli has investigated visual attention mechanism and saliency modeling along with their contribution to machine vision algorithms for different applications, including, fixation prediction, object detection and tracking, learning image features from image statistics and egocentric vision. He has also researched inferences from eye movements as a medium that may reveal one’s mind. In hisresearch, machine learning techniques within the span of Bayesian approaches and neural methods, in specific deep learning, have been developed and employed.
Talk at TEDxModenaSalon · 22 Nov 2017

Rita Cucchiara gave an invited talk at TEDxModenaSalon on the future of visual intelligence.
The recording of the talk is available on Youtube and on the video section of this website.
Invited Talk at Intel Nervana AI Academy · 15 Nov 2017

AImageLab will give a talk at the "Deep Learning for scientific research" workshop organized by Intel and Cineca.
Deep learning for Automatic Video Annotation and Captioning
Rita Cucchiara and Lorenzo Baraldi
Abstract
Automatic Video analysis can reach terrific results in structural and semantic annotation of content, tagging, similarity search, saliency detection and textual captioning. We will describe results achieved in this fileds with specifically designed convolutional neural networks and recurrent networks such as LSTM, trained over very large datasets of broadcast video in sport, movies and culture.
Seminario Prof. Simone Arcagni - · 27 Sep 2017

Venerdì 29 Settembre dalle ore 16 alle ore 17 presso la Sala Riunioni del Tecnopolo (Primo Piano) si terrà un seminario tenuto dal Prof. Simone Arcagni.
L'OCCHIO DELLA MACCHINA
Abstract:
"La scienza non ha nessun bisogno della filosofia per i suoi compiti. In compenso, quando un oggetto è scientificamente costruito con funzioni, per esempio una geometria spaziale, rimane cercare la filosofia che non è assolutamente attribuita alla funzione".
(Deleuze, Guattari, Che cos'è la filosofia?, Einaudi, Torino, 1996)
Lo sguardo e la visione sono questioni che attengono tanto agli studi sui media, alla filosofia e agli studi culturali, quanto a quelli legati alla scienza e alle tecnologie.
Questo seminario sarà un'introduzione alla logica culturale dello sguardo contemporaneo, agli aspetti culturali e alle relazioni sociali dell'occhio computazionale.
Alcune storie di incontri tra studi scientifici e studi umanistici dimostrano come sia fondamentale per entrambi i campi scambiare punti di vista e modelli di analisi per poter affrontare le proprie ricerche con strumentazioni sempre più adatte al soggetto di studi.
Sicurezza Stradale: Imagelab premiato a livello nazionale dalla fondazione ANIA · 22 Sep 2017

La tesi intitolata "Pose estimation tramite tecniche di deep learning per automotive", sviluppata all'interno del laboratorio ImageLab, ha vinto il premio nazionale ANIA come migliore lavoro dell'area tecnico-ingegneristica riguardante il tema della sicurezza stradale. Autore della tesi è Marco Venturelli, relatore la Prof.ssa Rita Cucchiara, correlatori il Prof. Roberto Vezzani e il dott. Guido Borghi.
Tale premio era riservato alle tesi di laurea magistrali e triennali discusse tra il 1° novembre 2015 e il 31 marzo 2017, ed è nato con l’idea di investire e di creare un’interazione con i giovani laureati che abbiano trattato ed approfondito, ognuno nel proprio campo d’interesse, il tema della sicurezza stradale, dando nuovi ed interessanti spunti.
Link alla notizia pubblicata su Repubblica: clicca qui
Clicca qui per maggiori informazioni riguardo al progetto di ricerca.
We are glad to announce that the Master's Thesis "Pose estimation tramite tecniche di deep learning per automotive" developed at ImageLab by Marco Venturelli, Rita Cucchiara, Roberto Vezzani and Guido Borghi has won the national contest about Road Security, promoted by ANIA.
News Link: click here
Click here for more info about the research project.
Rita Cucchiara's invited seminar to Stanford AI lab · 24 Jul 2017

Rita Cucchiara has given an invited talk to Stanford AI Lab on the 19 July, 2017.
Imagelab ranks first at the LSUN challenge @ CVPR17 · 20 Jul 2017

The latest saliency prediction model developed by Imagelab has ranked first in the LSUN 2017 saliency challenge.
Our model integrates an LSTM-based attentive mechanism to iteratively attend and refine predictions at different locations. A variation of that model is currently under submission to a journal. You can download the preprint of the paper here.
Thanks to: Marcella Cornia, Lorenzo Baraldi, Giuseppe Serra, Rita Cucchiara
MuMeT - Happy Hour Opening Ceremony · 16 Jun 2017

The second edition of a unique Master in Italy, with excellent career perspectives: advanced skills in Visual Computing, Computer Vision and Graphics, Machine Learning and AI. The Master is founded by MIUR and EC in Cluster Smart City and Communities.
Alessandro Capra (Director of Dep. Engineering “Enzo Ferrari”) and Rita Cucchiara (Master Director) will open the event with their greetings. Two welcome speakers Giorgio de Mitri (Sartoria Comunicazione) and Pietro Altoé (NVIDIA) will participate to the happy hour.
Visit event page for more details.
Imagelab @ International Vehicles Symposium (IV 2017), Los Angeles, California · 09 Jun 2017

Unimore Imagelab is attending at the "Intelligent Vehicles Symposium", one of the most important international conference about next smart vehicle generation that will be held at Redondo Beach, Los Angeles, California, from 11 to 14 June 2017.
Two PhD students, Stefano Alletto and Guido Borghi, are presenting two papers:
- Learning Where to Attend Like a Human Driver (A. Palazzi, F. Solera, S. Calderara, S. Alletto, R. Cucchiara)
- Embedded Recurrent Network for Head Pose Estimation in Car (G. Borghi, R. Gasparini, R. Vezzani, R. Cucchiara)
These works have been carried out within the project "FAR2015 - Monitoring the car driver’s attention with multisensory systems, computer vision and machine learning" funded by the University of Modena and Reggio Emilia.
We also acknowledge the CINECA award under the ISCRA initiative, for the availability of high-performance computing resources and support.
For more information please visit:
- Far Project
- Automotive research at Imagelab
Unimore in Israele a parlare di trasferimento tecnologico in high tech · 25 May 2017

Unimore in israele a parlare di trasferimento tecnologico in high tech
Israele, 20-26 Maggio 2017
Prof. Rita Cucchiara
Bologna, 12 aprile; Prof. Rita Cucchiara Computer VIsion for Industry in The Deep Learning Era · 11 Apr 2017

Bologna 12 Aprile 2017
prof. Rita Cucchiara
Two papers accepted @IV 2017 · 16 Mar 2017
Our papers:
- Learning Where to Attend Like a Human Driver (A. Palazzi, F. Solera, S. Calderara, S. Alletto, R. Cucchiara)
- Embedded Recurrent Network for Head Pose Estimation in Car (G. Borghi, R. Gasparini, R. Vezzani, R. Cucchiara)
have been accepted in IEEE Intelligent Vehicles Symposium (IV 2017).
Two papers accepted @CVPR · 09 Mar 2017

Our papers
- POSEidon: Face-from-Depth for Driver Pose Estimation (G. Borghi, M. Venturelli, R. Vezzani, R. Cucchiara)
- Hierarchical Boundary-Aware Neural Encoder for Video Captioning (L. Baraldi, C. Grana, R. Cucchiara)
have been accepted in CVPR 2017, that will take place at the Hawaii Convention Center from July 21 to July 26, 2017 in Honolulu, Hawaii.
In the meanwhile the e-version will be available, please take a look at the preliminar versions of the papers.
Seminario · 01 Mar 2017

"Visione artificiale: nuove applicazioni per il mondo della logistica integrata e scenari futuri"
seminario invitato Club ICT Confindustria Modena 27 febbraio 2017
prof. Rita Cucchiara Slides
Machine Vision in the deep learning era · 01 Feb 2017

Rita Cucchiara: Seminario invitato presso CRIT slides
Ingegneria dei Sistemi Intelligenti: Vision, Deep Learning e Cognitive Computing · 25 Jan 2017

Master MuMeT 2017 program presentation will take place during the event: Ingegneria dei Sistemi Intelligenti: Vision, Deep Learning e Cognitive Computing
Second edition of Master MuMeT on Visual Computing and Multimedia Technologies is starting! · 25 Jan 2017
MuMeT 2017 is an international Master of second level of the University of Modena and Reggio Emilia, co-sponsored by Italian MIUR (Ministero della Istruzione, Università e Ricerca) in the National Technology Clusters (project CittaEducante). MUMET II level Master wants to create new professional figures with advanced knowledge on the emerging technologies in visual computing, vision and machine learning, and intelligent multimedia systems.
The Master homepage can be found here.
Il fattore umano nelle auto a guida autonoma. Attenzione umana ed intelligenza artificiale · 18 Jan 2017

Rita Cucchiara and Annalisa Bargellini Talks @ Soroptimist Modena 18 jan 2017
Il fattore umano nelle auto a guida autonoma. Attenzione umana ed intelligenza artificiale
Invited talk "human behavior understanding in automotive and around" · 07 Nov 2016

Rita Cucchiara's invited talk at European Center of Living Technologies , Venezia 6 nov 2017
Invited talk "Visual Intelligence For Human And Machine" · 28 Oct 2016

Prof. Cucchiara presented a talk on "Visual Intelligence For Human And Machine" at STATE OF THE NET, Trieste 28-29 october 2016.
Multi-Camera Tracking: following people in large camera networks · 14 Oct 2016

Dr. Ergys Ristani is visiting ImageLab and he will give a talk on Multi-Camera Tracking on October, Tuesday 18th at 4pm in FA-0A
Multi-Camera Tracking is a canonical problem in computer vision which tries to determine "who is where" at all time across a large camera network. Typical applications include city-wide surveillance and airport/station monitoring.
Dr. Ergys Ristani is a PhD candidate at Duke University, under the supervision of Prof. Carlo Tomasi. His research interest include Multi-Target Tracking, Multi-Camera Tracking, and the estimation and tracking of motion boundaries.
To download the seminar flyer, please see: https://aimagelab.ing.unimore.it/imagelab/uploadedFiles/seminario_ristani_18_10_2016.pdf.
Spotting prejudice team @Imagelab press release · 03 Oct 2016

The Prejudice team of unimore composed by Imagelab memebers Andrea Palazzi, Simone Calderara and Rita Cucchiara has gained the attention of the scientific community with their recent work about "Spotting prejudice with nonverbal behaviours" presented at UBICOMP 2016.
Check out our "Prejudice dataset" here.
Attached a Press release of all articles that talk about our work on the web and in printed papers:
https://www.newscientist.com/article/mg23130933-200-camera-spots-your-hidden-prejudices-from-your-body-language/ http://www.dailymail.co.uk/sciencetech/article-3813425/Can-computer-tell-RACIST-Algorithm-detect-hidden-prejudice-person-s-body-language.html http://www.repubblica.it/tecnologia/2016/09/29/news/studio_razzismo_ecco_l_algoritmo_italiano_per_smascherare_i_pregiudizi_anche_inconsapevoli-148760996/ http://myinforms.com/en-gb/a/41993012-camera-spots-your-hidden-prejudices-from-your-body-language/ http://anglenews.com/can-a-computer-tell-if-youre-racist-algorithm-can-detect-hidden-prejudice-from-a-persons-body-language/ http://tech.fanpage.it/l-algoritmo-italiano-che-svela-razzismo-e-pregiudizi/ https://www.tomshw.it/l-algoritmo-italiano-per-smascherare-razzismo-e-pregiudizi-80376 https://www.bcrmagazine.it/201633983/razzismo-ecco-lalgoritmo-italiano-per-smascherare-i-pregiudizi-anche-inconsapevoli.php http://23on.com/razzismo-ecco-lalgoritmo-italiano-per-smascherare-i-pregiudizi-anche-inconsapevoli/ http://www.modicanews.com/can-a-computer-tell-if-youre-racist-algorithm-can-detect-hidden-prejudice-from-a-persons-body-language/ http://huntnews.in/p/detail/2821262581067916?uc_param_str=dnfrpfbivesscpgimibtbmntnijblauputoggdnw&pos=1475155800173&channel=technology&chncat=category_english http://ebalsblog.blogspot.it/2016/09/can-computer-tell-if-youre-racist-new.html http://www.looooker.com/archives/34774 http://newsfeeds.pegitboard.com/news/can-a-computer-tell-if-you-re-racist-algorithm-can-detect-hidden-prejudice-from-a-person-s-body-language?uid=24563
New Scientist features ImageLab research about recognition of non-verbal behaviours · 29 Sep 2016

The international science magazine New Scientist, based in UK, talks about the ImageLab research about recognition of non-verbal behaviours in one of its cover articles. The link to the article for the online version of the science magazine can be found here: https://www.newscientist.com/article/mg23130933-200-camera-spots-your-hidden-prejudices-from-your-body-language/.
ImageLab algorithm in OpenCV · 26 Sep 2016

OpenCV accepted our Connected Components Labeling algorithm into their official source code. From the next release, our contribution will be the official one, recognizing its superior performance.
OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. The library has more than 2500 optimized algorithms, which includes a comprehensive set of both classic and state-of-the-art computer vision and machine learning algorithms. These algorithms can be used to detect and recognize faces, identify objects, classify human actions in videos, track camera movements, track moving objects, extract 3D models of objects, produce 3D point clouds from stereo cameras, stitch images together to produce a high resolution image of an entire scene, find similar images from an image database, remove red eyes from images taken using flash, follow eye movements, recognize scenery and establish markers to overlay it with augmented reality, etc. OpenCV has more than 47 thousand people of user community and estimated number of downloads exceeding 7 million. The library is used extensively in companies, research groups and by governmental bodies.
Facebook AI Research Partnership · 29 Aug 2016

Facebook has selected Imagelab as one of the 15 world-class research labs in Europe to receive a GPU-based server as part of the Facebook AI Research Partnership. Our application has been selected from a large pool of universities and research institutes working on important and innovative research. Facebook is committed to building strong research partnerships with institutions throughout Europe, and ensuring that Facebook's partners have the necessary hardware and tools to continue tackling some of the most important challenges in the disciplines of artificial intelligence and machine learning. Thanks to Lorenzo Baraldi, Costantino Grana and Simone Calderara!
Read more on the Facebook Research blog.
Report of Dagstuhl Seminar - Eyewear Computing · 19 Jul 2016

Here the report of the Seminar "Eyewear Computing - Augmenting the Human with Head-Mounted Wearable Assistants", 24–29 Januar 2016, Dagstuhl.
Invited talk alla scuola vismac 16 giugno 2016 · 16 Jun 2016

Prof. Cucchiara presented a talk on "Human Motion Understanding" at the GIRPR - VISMAC2016 summer school.
First International Workshop on Egocentric Perception, Interaction and Computing · 24 May 2016

ImageLab is organising the First International Workshop on Egocentric Perception, Interaction and Computing (EPIC@ECCV16) that will be held on the October 8-10, 2016, in conjunction with the European Conference on Computer Vision, Amsterdam, The Netherlands. Its goal is to give an overview of the recent technologies and system solutions, create a forum to exchange ideas and address challenges emerging in this field.
Talk by Prof. Tal Hassner · 17 May 2016

Prof. Tal Hassner (The Open University of Israel) is visiting Imagelab and is giving a talk on
"Faces, deep learning and the pursuit of training data"
Tuesday May 17, 2016 - 02:00 p.m. - Aula P 0.2 ex FA-0A
Abstract: The abilities of machines to detect and recognize faces improved remarkably over the last few years. This progress can at least partially be explained by the sizes of the training sets used to train deep learning models: huge numbers of face images downloaded and manually labeled. It is not clear, however, if the formidable task of collecting and labeling so many images is truly necessary. I will discuss the problems of data collection and describe a number of effective techniques for maximizing deep learning capabilities when collecting additional data is not an option. Importantly, though this talk will focus on face processing related tasks, these techniques can be applied in other image understanding problems where obtaining enough labeled examples for training deep learning systems is hard.
Nuovi sistemi intelligenti - Il Deep Learning per l'impresa del futuro · 16 Apr 2016

Il 16 maggio 2016 presso l'Auditorium del Tecnopolo di Modena si terrà una giornata dedicata al Deep Learning per l'impresa del futuro. Nel corso dell’iniziativa verranno presentate soluzioni, piattaforme software ed infrastrutture utilizzabili per portare il deep learning e le tecniche avanzate di apprendimento automatico nell’impresa, con testimonianze internazionali, accademiche e industriali. Seguirà una tavola rotonda sul loro utilizzo nell'industria e nell'impresa del futuro.
Per informazioni e registrazione: Pagina dedicata all'evento
Startcup regionale e PNI nazionale 2016 · 12 Apr 2016

Il 26 aprile si aprirà il bando per la Startcup Regionale, la competizione per favorire la nascita delle nuove imprese ad alto contenuto innovativo. Si rivolge a persone singole o gruppi interessati a sviluppare idee imprenditoriali innovative e/o ad alto grado di conoscenza. Le migliori idee imprenditoriali parteciperanno al Premio Nazionale Innovazione PNI Italia che si terrà a Modena ospitato da UNIMORE a dicembre 2016.
Per informazioni e contatti: http://www.unimore.it/evidenza/pni2016.html
Talk at "R&D: da Giovani Idee, Grandi Progetti" · 08 Apr 2016

In the context of the talk serie "R&D: da Giovani Idee, Grandi Progetti", Imagelab and Samsung will give a joint talk on 14/04/2016. Ing. Alletto Stefano will present the latest research efforts in the field of wearable computing, internet of things and object recognition. For further information please refer to the talk organizers' website: www.ideelab.it
Rita Cucchiara's interview at TGR TV News · 16 Mar 2016

Prof. Rita Cucchiara explains to the journalists of TV news TGR some of the last results obtained in the project Città Educante, in the context of exploting the new technologies to favour the acceptance of diversity in the primary schools.
The video can be found here.
Rita Cucchiara's talk at Area Chiar CVPR Workshop Vancouver 29 Feb 2015 · 01 Mar 2016

Rita Cucchiara's talk at Area Chair CVPR Workshop Vancouver 29 Feb 2015 can be downloaded here.
Hardware Grants from Nvidia and Cineca · 10 Feb 2016

Imagelab has received two important hardware grants:
-
The NVIDIA Hardware Grant, with the donation of one Tesla K40 GPU.
-
The Italian Supercomputing Resource Allocation (ISCRA) Grant from CINECA, which gives Imagelab access to the Galileo HPC Platform, containg 16 Tesla K80 GPUs.
The granted hardware will be mainly employed in the research project "Deep Learning in videos: concept detection and temporal video segmentation", as well as for other Imagelab activities.
Computer Vision Foundation: Advisory board · 04 Feb 2016

The Computer Vision Foundation appointed the new Advisory Board, chaired by Rene Vidal, composed by Anthony Hoogs, David Forsyth, Dimitri Metaxas,
Josef Sivic ,Kyoung Mu Lee ,Kyros Kutulakos ,Martial Hebert ,Rita Cucchiara ,Ruzena Bajcsy, Stan Sclaroff, Sven Dickinson, and Philip Torr.
Seminario Prof. Antonino Mazzeo · 02 Dec 2015

"Metodi, ambienti IDE, architetture e tecnologie per la progettazione dei sistemi digitali embedded".
Abstract: Il seminario intende focalizzarsi, con riferimento a specifici domini applicativi quali quelli dell’automotive dell’aerospazio e del ferroviario, sulla progettazione dei sistemi digitali embedded ad elevata complessità e assoggettati a vincoli di sicurezza, affidabilità, real-time e time to market e, in particolare, sugli aspetti delle differenti soluzioni oggi consentite dalle correnti tecnologie VLSI inquadrate in vari contesti architetturali dedicati (sistemi dedicati, general purpose e misti realizzati su FPGA, SoC e MPSoC ) e sulle metodologie di sviluppo a supporto.
Sono disponibili i lucidi del seminario al seguente indirizzo
Vision for cultural heritage · 25 Nov 2015

Mercoledì 25 e Giovedì 26 Novembre ImageLab/Softech-ICT ospiterà l'evento "Vision for cultural heritage", nell'ambito del progetto Dicet.
Il programma e il materiale dell'evento sono disponibili al seguente link: Vision for cultural heritage
Lectures by Prof. Nadia Magnenat Thalmann · 25 Sep 2015

Professor Nadia Magnenat Thalmann, Director of the Institute for Media Innovation in Singapore, and head of the MIRALab Research Laboratory at the University of Geneva, is visiting Imagelab and is going to give four lectures on Computer Graphics and 3D Reconstruction. (more info)
Tutorial at CAIP 2015 · 01 Sep 2015

Costantino Grana and Giuseppe Serra gave a tutorial at the International Conference on Computer Analysis of Images and Patterns in Malta on The Bag of Visual Words model and recent advancements in image classification. Tutorial slides
International Workshop on Wearable and Ego-vision Systems for Augmented Experience (WEsAX) · 03 Jul 2015

ImageLab is organising the first International Workshop on Wearable and Ego-vision Systems for Augmented Experience (WEsAX) that will be held on the July 3, 2015, in conjunction with the IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy. The goal of the first International Workshop on Wearable and Ego-vision Systems for Augmented Experience (WEsAX) is to give an overview of the recent technologies and system solutions, create a forum to exchange ideas and address challenges emerging in this field.
Lecture by Ing. Alessio Bazzica · 22 May 2015

Ing Alessio Bazzica is visiting Imagelab and is going to present a lecture on
Discovering the Music Information Retrieval Field
(Friday May 22, 2015 - 9:00am - Aula FA-1D )
Alessio Bazzica received the M.S. degree in Computer Engineering from the University of Florence (Italy) in 2012 and is now a 3nd year PhD candidate at the Multimedia Computing (MMC) Group in Delft (The Netherlands). He is interested in multimedia information retrieval and he is currently working on multimodal and crossmodal approaches for music information retrieval.
Attivazione master di II livello - MUMET · 08 May 2015

Al via il nuovo Master MUMET. Il master vuole creare nuove figure professionali (MULTIMEDIA DATA SCIENTIST), con competenze avanzate sulle tecnologie informatiche multimediali e sul visualcomputing, competenze attualmente molto rare ed assai richieste per i sistemi, servizi ed applicazioni nelle smartcities and communities.
Sito web del Master in "Visual Computing and Multimedia technologies"
Workshop tematico - "New Ideas for Education in Smart Communities" · 20 Apr 2015
Il progetto Città Educante ha lo scopo di ripensare radicalmente l'ambiente di apprendimento, attraverso l'applicazione delle più avanzate tecnologie informatiche. Il workshop, ad invito e a partecipazione libera, ha come obiettivo lo scambio di idee e la disseminazione delle attività svolte dai partners durante il primo anno di progetto.
L'evento che si inserisce tra la manifestazioni per i 25 anni di Ingegneria a Modena si svolgerà lunedì 20 aprile 2015, ore 10:00, presso l'aula P 0.5 (FA-0-D), del Dipartimento di Ingegneria "Enzo Ferrari".
Sito web del workshop "New Ideas for Education in Smart Communities"
Best Paper award @ AVSS2015 · 08 Jan 2015

Towards the evaluation of reproducible robustness in tracking-by-detection won the best paper award at AVSS 2015 Conference. Take your time to check the project page
Group Detection Paper accepted @TPAMI · 08 Jan 2015

Our paper "Socially Constrained Structural Learning for Groups Detection in Crowd " have been accepted in TPAMI. In the meanwhile the e-version will be available, please take a look at our dataset and code and for more details the preliminar version of the paper.
Special Issue on: Wearable and Ego-vision Systems for Augmented Experience · 08 Jan 2015
The rapid progress in the development of low-level component technologies such as wearable cameras, wearable sensors, wearable displays and wearable computers is making it possible to augment everyday living. Wearable and egocentric vision systems can be exploited to analyze multi-modal data types (e.g. video, audio, motion) and to support understanding human interactions with the world (including gesture recognition, action recognition, social interaction recognition). Based on the processing of such data, wearable systems can be used to enhance our capabilities and augment our perception. State-of-the-art techniques for wearable sensing can support assistive technologies and advanced perception. This special issue intends to highlight research in support for human performance through egocentric sensing .
Best paper at INTETAIN 2015 · 08 Jan 2015

The paper “ Wearable Vision for Retrieving Architectural Details in Augmented Tourist Experiences ” by Stefano Alletto, Davide Abati, Giuseppe Serra and Rita Cucchiara was awarded the best paper award at INTETAIN in Turin. In this paper we propose an egocentric vision system to enhance tourists’ cultural heritage experience. Exploiting a wearable board and a glass-mounted camera, the visitor can retrieve architectural details of the historical building he is observing and receive related multimedia contents. To obtain an effective retrieval procedure we propose a visual descriptor based on the covariance of local features. Differently than the common Bag of Words approaches our feature vector does not rely on a generated visual vocabulary, removing the dependence from a specific dataset and obtaining a reduction of the computational cost. 3D modeling is used to achieve a precise visitor’s localization that allows browsing visible relevant details that the user may otherwise miss. Experimental results conducted on a publicly available cultural heritage dataset show that the proposed feature descriptor outperforms Bag of Words techniques.
Seminario Nvidia · 17 Nov 2014

Lunedì 17 Novembre 2014 dalle 14.00 alle 16.15 presso l'Aula P0.4 (ex FA-0C) - dipartimento DIEF - si terrà un seminario sulle architetture parallele GPU Nvidia.
14:00-15:00: Edmondo Orlotti, Business Development NVIDIA "Tecnologie per il calcolo parallelo e la visualizzazione, dal cloud al mobile"
15:00-16:15: Carlo Nardone, Solution Architect NVIDIA, "Gli strumenti di sviluppo per la programmazione in ambiente GPU". Locandina
Slides: Parte 1, Parte 2, Parte 3.
Eighth edition of the ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC 2014) · 04 Nov 2014

The eighth edition of the ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC) will be held in Venezia, ITALY.
Public website: http://imagelab.ing.unimore.it/icdsc14
Invited talk at the ECCV workshop · 08 Jan 2014

Prof. Cucchiara is presenting a talk on "Computer Vision for interactive experiences with art and artistic documents" at the ECCV workshop "Where Computer Vision Meets Art - VISART2014.
2nd International Workshop on Multimedia for Cultural Heritage · 09 Sep 2013

The 2nd International Workshop on Multimedia for Cultural Heritage, will be held on the 9-10th of September 2013, in conjunction with the 17th International Conference on Image Analysis and Processing (ICIAP), Naples, Italy, aims to be a profitable informal working day to discuss together hot topics in multimedia applied to cultural heritage.
Public website: http://imagelab.ing.unimore.it/MM4CH2013/
S5 - Second Short Spring School in Surveillance (Modena, May 7-9 2013) · 07 May 2013

This short 3-day school is meant to provide a self-contained comprehensive introduction to modern video surveillance methods and techniques, with a good balance between theory and practical applications.
This school is open to researchers, PhD and undergraduate students, scholars in the field of surveillance and security, and is conceived also for technicians from both industries and public entities.
Public website: http://imagelab.ing.unimore.it/s5/
3dPes · 12 Jan 2013

3DPeS (3D People Surveillance Dataset) is a new surveillance dataset, designed mainly for people re-identification in multi camera systems with non-overlapped field of views, but also applicable to many other tasks, such as people detection, tracking, action analysis and trajectory analysis.
Differently from other re-identification datasets here data for the complete processing chain are available: the camera setting and the 3D environment reconstruction, the hundreds of recorded videos, the camera calibration parameters, the identity of the hundreds of people, detected more than one time by different point of view.
Dataset web site: 3DPeS
S4 - Short Spring School in Surveillance · 17 May 2011
This short 3-day school is meant to provide a self-contained comprehensive introduction to modern video surveillance methods and techniques, with a good balance between theory and practical applications.
This school is open to PhD and undergraduate students, scholars in the field of surveillance and security, and is conceived also for technicians from both industries and public entities.
Public website: http://imagelab.ing.unimore.it/s4/
Multimedia in Forensics - MiFor2009 · 23 Oct 2009

With the proliferation of multimedia data on the web, surveillance cameras in cities, and mobile phones in everyday life we see an enormous growth in multimedia data that needs to be analyzed by forensic investigators. The sheer volume of such datasets makes manual inspection of all data impossible. Tools are needed to support the investigator in their quest for relevant clues and evidence and in their strive towards preventing crime.
The multimedia community has developed new solutions for management of large collections of video footage, images, audio and other multimedia content, knowledge extraction and categorization, pattern recognition, indexing and retrieval, searching, browsing and visualization, and modeling and simulation in various domains. Due to the inherent uncertainty and complexity of forensic data, applying those techniques to forensic data is not straightforward.
The time is ripe to tailor these results for forensics. Multimedia in forensics is the workshop aims at joining the topics and their communities.
This workshop aims at addressing the multimedia toolbox supporting the forensic process from the prevention of crime, capturing and annotation of the crime scene, the investigation of the data in the lab, up to the presentation of the results in court. It is a first attempt in bringing multimedia tools in to this exciting application field. Target audience are researchers working on innovative technology, representatives from companies developing tools, and forensic investigators in various disciplines
Presente e Futuro dei sistemi di Videosorveglianza per la sicurezza urbana · 20 Feb 2009

Il Comune di Modena e il Dipartimento di Ingegneria dell'Informazione dell'Università di Modena e Reggio Emilia organizzano il convegno "Presente e Futuro della Videosorveglianza per la sicurezza urbana" il giorno 20 Febbraio 2009 presso la sala della Fondazione Biagi.
L'argomento è la videosorveglianza e il trattamento dei dati video sia in tempo reale, per la prevenzione e la salvaguardia del cittadini, sia a posteriori per l'analisi forense e il supporto nelle fasi processuali.
Iciap 2007 · 12 Sep 2007

Imagelab organized the 14th International Conference on Image Analysis and Processing (ICIAP2007).
VSSN 2006 · 27 Oct 2006

Following a successful tradition, this will be the fourth edition of the VSSN Workshop to be held in conjunction with ACM Conference of Multimedia 2006 at Santa Barbara, California, October 22-28, 2006.
Workshop web site: http://imagelab.ing.unimore.it/vssn06
VSSN 2005 · 11 Nov 2005
Rita Cucchiara was program chair of VSSN 2005, the 3rd ACM International Workshop on Video Surveillance & Sensor Networks in conjunction with ACM Multimedia 2005.
Event web site: http://imagelab.ing.unimore.it/vssn05/
1st Workshop on In-Vehicle Cognitive Computer Vision Systems (IVCCVS2003) · 03 Apr 2003

1st Workshop on In-Vehicle Cognitive Computer Vision Systems (IVC2VS)
in conjunction with 3rd International Conference on Computer Vision Systems (ICVS) http://dib.joanneum.at/ICVS03/
CONVENTION CENTER, GRAZ, Austria - April 3, 2003