

Indexing of Historical Handwritten Documents
This project, named XDOCS, is designed with the intention of extending to a much wider audience of scholars, or even simply curious people, the possibility to access a variety of historical documents published on the web. To that purpose, the project is developing an innovative data capturing technique able to extract document indexes in quasi-automatic mode from their handwritten contents. The devised solution intervenes after the dematerialisation action of scanning the historic documents and obtaining one image per couple of adjacent pages, and it is intended to be especially applied to a long series of documents such as the large number of civil registries that are available since the constitution of the Italian state.

Due to the great amount of variability in handwriting and the high noise levels in historical documents, handwritten historical documents are currently transcribed by hand. This means that each occurrence of a word in a text must be annotated. The goal of the word spotting idea applied to handwritten documents is to greatly reduce the amount of annotation work that has to be performed, by grouping all words into clusters. Ideally, each cluster contains words with the same annotation. This project aim to apply this strategy on historical documents of birth act of nineteenth century belonging to the Italian state constitution.
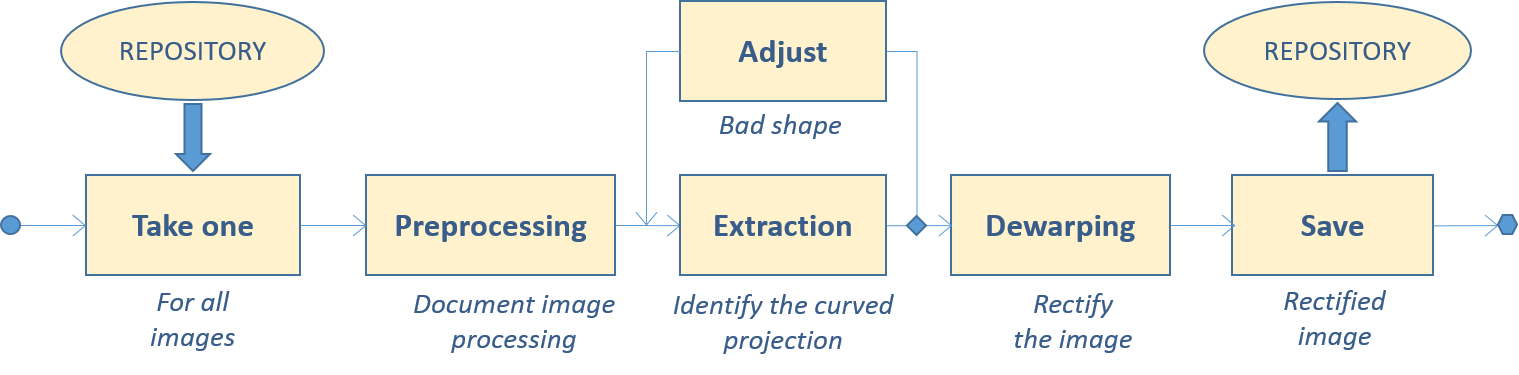
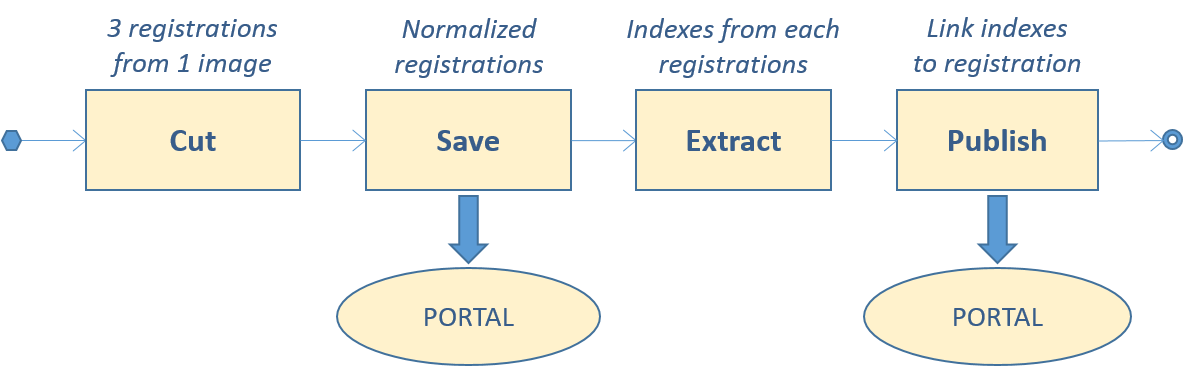
The XDOCS indexing process is split into two main phases, namely "image rectification" and "indexing & publication". Both phases are depicted in the figure below. The former displays the steps that move from a scanned image up to its final squaring. This step essentially transforms the original curled document pages into ones constituted only of horizontal straight text lines, without any distortion due to perspective, lenses and page warping. The latter phase of the indexing process, instead, cuts individual registrations from the rectified image and lead to indexing each of those registrations using word spotting technique.
In order to evaluate the performance of the adopted word spotting technique we also release a group of datasets of handwritten word images taken from the Italian registries. All images contain month names and were automatically extracted from the original document by our semiautomatic system.
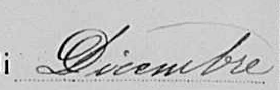




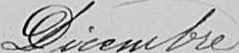
Publications
| 1 |
Bolelli, Federico; Borghi, Guido; Grana, Costantino
"XDOCS: An Application to Index Historical Documents"
Digital Libraries and Multimedia Archives,
vol. 806,
Udine, Italy,
pp. 151
-162
,
Jan 25-26,
2018
| DOI: 10.1007/978-3-319-73165-0_15
Conference

|
| 2 |
Bolelli, Federico; Borghi, Guido; Grana, Costantino
"Historical Handwritten Text Images Word Spotting through Sliding Window HOG Features"
Image Analysis and Processing - ICIAP 2017,
vol. 10484,
Catania, Italy,
pp. 729
-738
,
Sep 11-15,
2017
| DOI: 10.1007/978-3-319-68560-1_65
Conference
|
| 3 |
Bolelli, Federico
"Indexing of Historical Document Images: Ad Hoc Dewarping Technique for Handwritten Text"
Digital Libraries and Archives,
vol. 733,
Modena, Italy,
pp. 45
-55
,
Jan 26-27,
2017
| DOI: 10.1007/978-3-319-68130-6_4
Conference
|
Project Info
