

Visual Saliency Prediction
When human observers look at an image, attentive mechanisms drive their gazes towards salient regions. Emulating such ability has been studied for more than 80 years by neuroscientists and by computer vision researchers, while only recently, thanks to the large spread of deep learning, saliency prediction models have achieved a considerable improvement. Motivated by the importance of automatically estimating the human focus of attention on images, we developed two different saliency prediction models which have overcome previous methods by a big margin winning the LSUN Saliency Challenge at CVPR17, Honolulu, Hawaii.

Saliency Attentive Model (SAM)
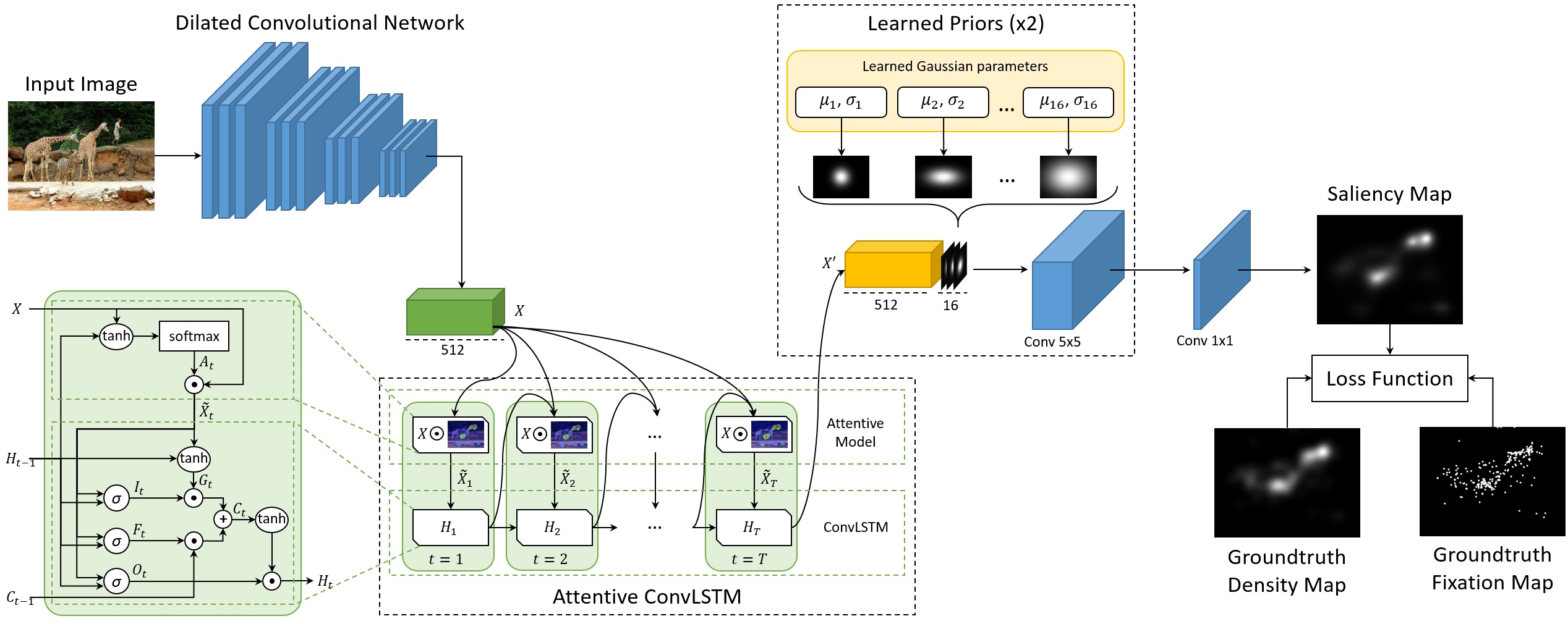
Data-driven saliency has recently gained a lot of attention thanks to the use of Convolutional Neural Networks for predicting gaze fixations. In this paper we go beyond standard approaches to saliency prediction, in which gaze maps are computed with a feed-forward network, and we present a novel model which can predict accurate saliency maps by incorporating neural attentive mechanisms. The core of our solution is a Convolutional LSTM that focuses on the most salient regions of the input image to iteratively refine the predicted saliency map. Additionally, to tackle the center bias present in human eye fixations, our model can learn a set of prior maps generated with Gaussian functions. We show, through an extensive evaluation, that the proposed architecture overcomes the current state of the art on two public saliency prediction datasets. We further study the contribution of each key components to demonstrate their robustness on different scenarios.
Paper

Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model
M.Cornia, L.Baraldi, G.Serra, R.Cucchiara
IEEE Transactions on Image Processing, 2018
LSUN Challenge 2017
Our Saliency Attentive Model (SAM) has ranked first in the LSUN 2017 Saliency Challenge, which took place at CVPR, Honolulu, Hawaii.
Posters
Multi-Level Network (ML-Net)
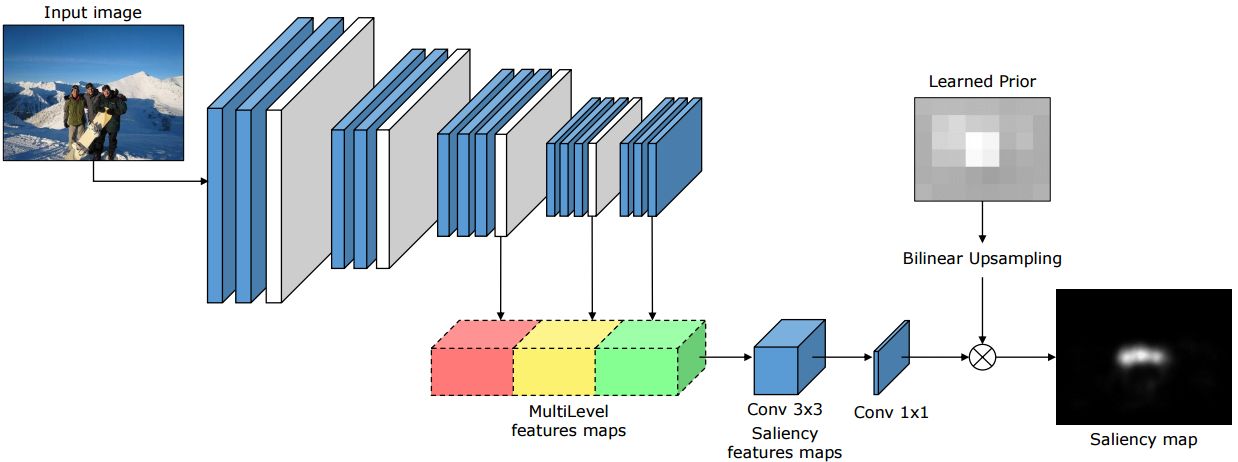
Current state of the art models for saliency prediction employ Fully Convolutional networks that perform a non-linear combination of features extracted from the last convolutional layer to predict saliency maps. We propose an architecture which, instead, combines features extracted at different levels of a Convolutional Neural Network (CNN). Our model is composed of three main blocks: a feature extraction CNN, a feature encoding network, that weights low and high level feature maps, and a prior learning network. We compare our solution with state of the art saliency models on two public benchmarks datasets. Results show that our model outperforms under all evaluation metrics on the SALICON dataset, which is currently the largest public dataset for saliency prediction, and achieves competitive results on the MIT300 benchmark.
Paper

A Deep Multi-Level Network for Saliency Prediction
M.Cornia, L.Baraldi, G.Serra, R.Cucchiara
ICPR 2016
Posters
- Poster from "Women in Computer Vision" - CVPR 2016 Workshop
- Poster from "Assistive Computer Vision and Robotics" - ECCV 2016 Workshop
- Poster from ICPR 2016
Publications
| 1 |
Cornia, Marcella; Abati, Davide; Baraldi, Lorenzo; Palazzi, Andrea; Calderara, Simone; Cucchiara, Rita
"Attentive Models in Vision: Computing Saliency Maps in the Deep Learning Era"
INTELLIGENZA ARTIFICIALE,
vol. 12,
y,
pp. 161
-175
,
z,
2018
| DOI: 10.3233/IA-170033
Journal

|
| 2 |
Cornia, Marcella; Baraldi, Lorenzo; Serra, Giuseppe; Cucchiara, Rita
"Predicting Human Eye Fixations via an LSTM-based Saliency Attentive Model"
IEEE TRANSACTIONS ON IMAGE PROCESSING,
vol. 27,
pp. 5142
-5154
,
2018
| DOI: 10.1109/TIP.2018.2851672
Journal
|
| 3 |
Cornia, Marcella; Baraldi, Lorenzo; Serra, Giuseppe; Cucchiara, Rita
"SAM: Pushing the Limits of Saliency Prediction Models"
2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops,
Salt Lake City,
pp. 1971
-1973
,
June 18-22 2018,
2018
| DOI: 10.1109/CVPRW.2018.00250
Conference
|
| 4 |
Cornia, Marcella; Abati, Davide; Baraldi, Lorenzo; Palazzi, Andrea; Calderara, Simone; Cucchiara, Rita
"Attentive Models in Vision: Computing Saliency Maps in the Deep Learning Era"
AI*IA 2017 Advances in Artificial Intelligence,
vol. 10640,
Bari, Italy,
pp. 387
-399
,
November 14-17, 2017,
2017
| DOI: 10.1007/978-3-319-70169-1_29
Conference
|
| 5 |
Cornia, Marcella; Baraldi, Lorenzo; Serra, Giuseppe; Cucchiara, Rita
"Visual Saliency for Image Captioning in New Multimedia Services"
Multimedia & Expo Workshops (ICMEW), 2017 IEEE International Conference on,
Hong Kong,
pp. 309
-314
,
July 10-14, 2017,
2017
| DOI: 10.1109/ICMEW.2017.8026277
Conference
|
| 6 |
Cornia, Marcella; Baraldi, Lorenzo; Serra, Giuseppe; Cucchiara, Rita
"A Deep Multi-Level Network for Saliency Prediction"
Pattern Recognition (ICPR), 2016 23rd International Conference on,
Cancun, Mexico,
4-8 Dec 2016,
2016
| DOI: 10.1109/ICPR.2016.7900174
Conference
|
| 7 |
Cornia, Marcella; Baraldi, Lorenzo; Serra, Giuseppe; Cucchiara, Rita
"Multi-Level Net: a Visual Saliency Prediction Model"
Computer Vision – ECCV 2016 Workshops,
vol. 9914,
Amsterdam, The Netherlands,
pp. 302
-315
,
October 9th, 2016,
2016
| DOI: 10.1007/978-3-319-48881-3_21
Conference
|
