

Video Captioning with Naming
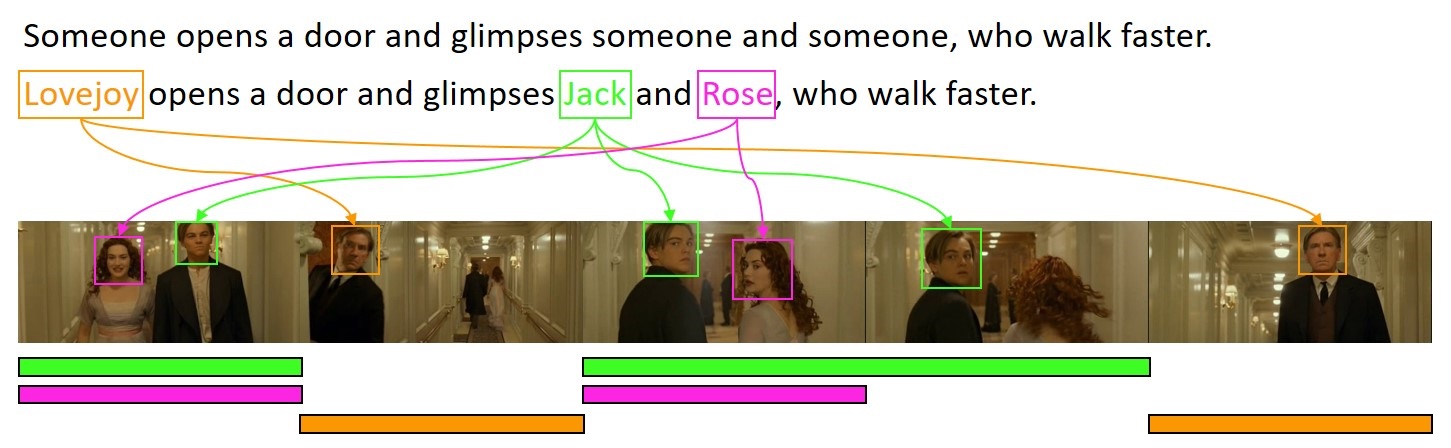
Current approaches for movie description lack the ability to name characters with their proper names, and can only indicate people with a generic "someone" tag. We developed two contributions towards the development of video description architectures with naming capabilities: firstly, we collected and released an extension of the popular Montreal Video Annotation Dataset in which the visual appearance of each character is linked both through time and to textual mentions in captions. We annotated, in a semi-automatic manner, a total of 63k face tracks and 34k textual mentions on 92 movies. Moreover, to underline and quantify the challenges of the task of generating captions with names, we presented different multi-modal approaches to solve the problem on already generated captions.
M-VAD Names Dataset
The dataset contains the annotations of the characters' visual appearances, in the form of tracks of face bounding boxes, and the associations with the characters' textual mentions, when available. We detect and annotate the visual appearances of characters in each video clip of each movie through a semi-automatic approach. The released dataset contains more than 24k annotated video clips, including 63k visual tracks and 34k textual mentions, all associated with their character identities.


The dataset can be downloaded at the following GitHub repository: M-VAD Names Dataset.


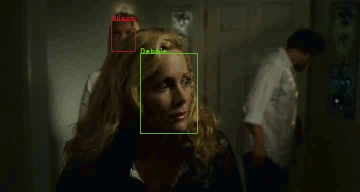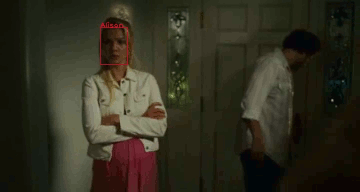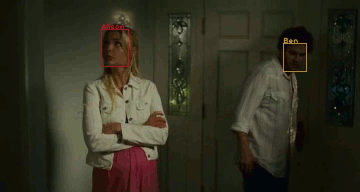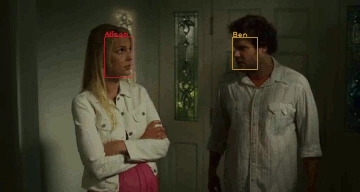


M-VAD Names: a Dataset for Video Captioning with Naming
S. Pini, M.Cornia, F. Bolelli, L.Baraldi, R.Cucchiara
Multimedia Tools and Applications, 2018
Towards Video Captioning with Naming: a Novel Dataset and a Multi-Modal Approach
S. Pini, M.Cornia, L.Baraldi, R.Cucchiara
International Conference on Image Analysis and Processing, 2017
Publications
| 1 |
Pini, Stefano; Cornia, Marcella; Bolelli, Federico; Baraldi, Lorenzo; Cucchiara, Rita
"M-VAD Names: a Dataset for Video Captioning with Naming"
MULTIMEDIA TOOLS AND APPLICATIONS,
vol. 78,
pp. 14007
-14027
,
2019
| DOI: 10.1007/s11042-018-7040-z
Journal

|
| 2 |
Pini, Stefano; Cornia, Marcella; Baraldi, Lorenzo; Cucchiara, Rita
"Towards Video Captioning with Naming: a Novel Dataset and a Multi-Modal Approach"
Image Analysis and Processing - ICIAP 2017,
vol. 10485,
Catania, Italy,
pp. 384
-395
,
11-15 September 2017,
2017
| DOI: 10.1007/978-3-319-68548-9_36
Conference
|
