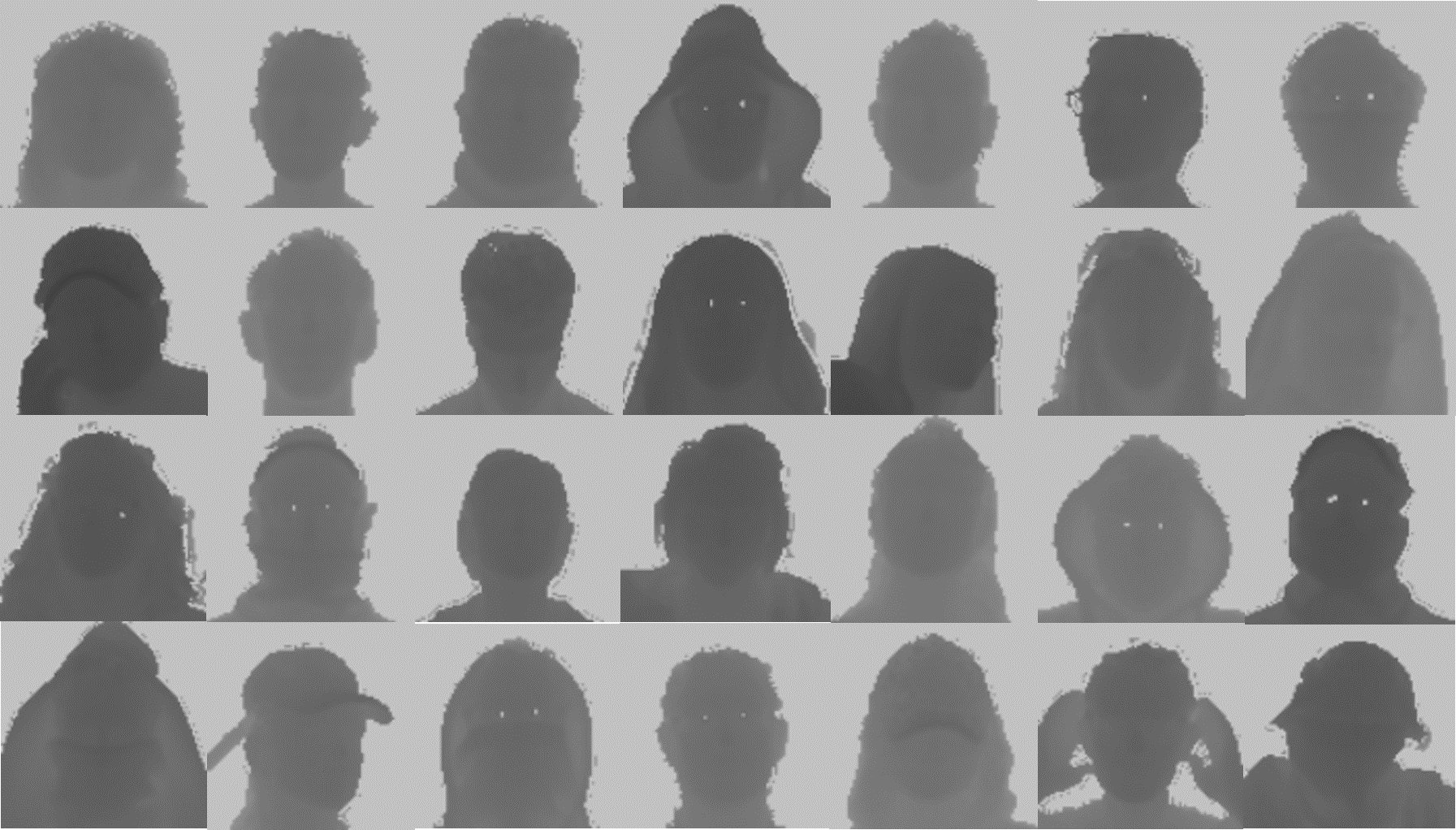POSEidon: Face-from-Depth for Driver Pose Estimation
Guido Borghi Marco Venturelli Roberto Vezzani Rita Cucchiara
Abstract
Fast and accurate upper-body and head pose estimation is a key task for automatic monitoring of driver attention, a challenging context characterized by severe illumination changes, occlusions and extreme poses.
In this work, we present a new deep learning framework for head localization and pose estimation on depth images.
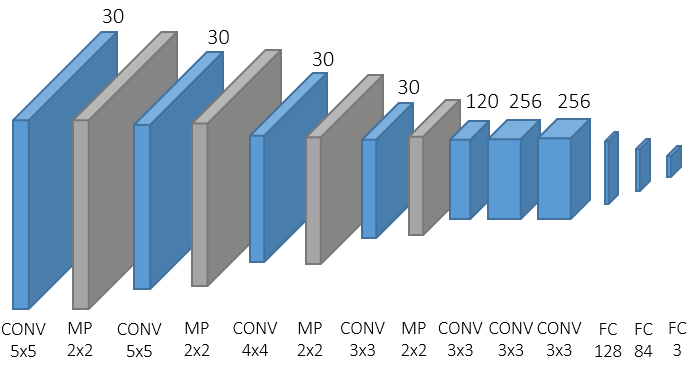
The core of the proposal is a regression neural network, called POSEidon, which is composed of three independent convolutional nets followed by a fusion layer, specially conceived for understanding the pose by depth.
In addition, to recover the intrinsic value of face appearance for understanding head position and orientation, we propose a new Face-from-Depth approach for learning image faces from depth.
Results in face reconstruction are qualitatively impressive.
We test the proposed framework on two public datasets, namely Biwi Kinect Head Pose and ICT-3DHP, and on Pandora, a new challenging dataset mainly inspired by the automotive setup.
Results show that our method overcomes all recent state-of-art works, running in real time at more than 30 frames per second.
POSEidon Framework
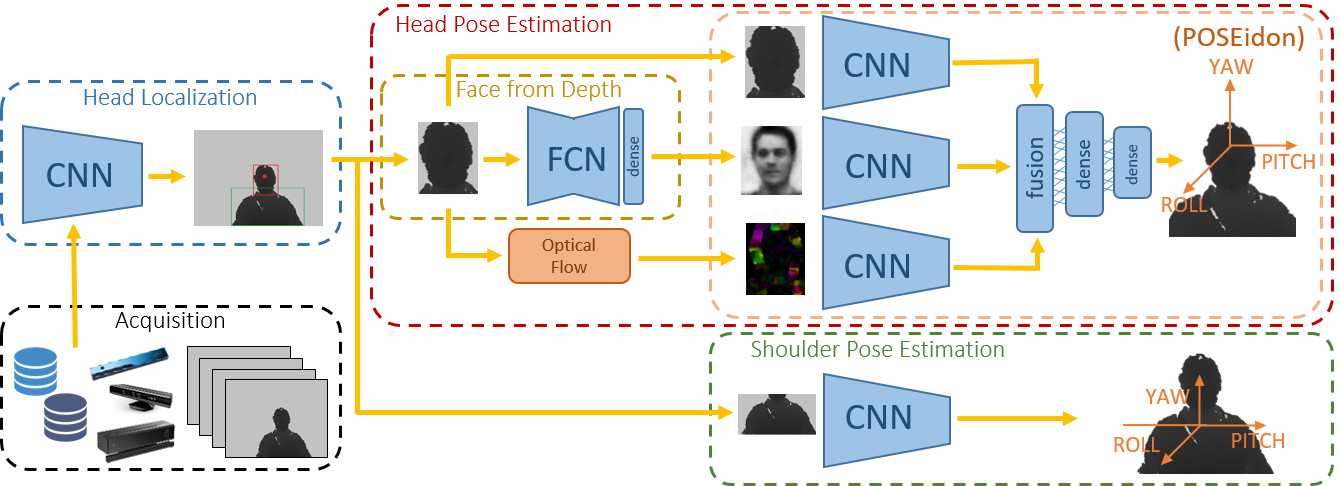
Overview of the whole POSEidon framework.
Depth input images are acquired by low cost sensors (black) and provided to a Head Localization CNN (blue) to suitably crop the images around the upper-body or head regions.
The first is exploited by the shoulder pose estimation task (green), while the second is selected for the head pose estimation (red) obtained through the POSEidon network (orange).
In the center, the Face-from-Depth net (yellow) which produces gray-level images of the face from the depth map.
Weights are intended for Keras applications with Theano backend.
FAQs
- Where can I find the code? Here (Keras + Theano + Biwi dataset)
- What about background suppression? We made background suppression applying a percentile-based constrast stretching only on certain pixel values. For example, look the code at line 124 of loadBIWI.py.
- What about normalization of input data? As reported in the original paper, data are normalized to obtain zero mean and unit variance. For example, look at line 125 and 133 of loadBIWI.py.
- How input images are resized?We used the resize method in the OpenCV libraries.
- How is the final output of the model? Output angles are centered in 0, so output values are going to be both positives and negatives.
Face-from-Depth
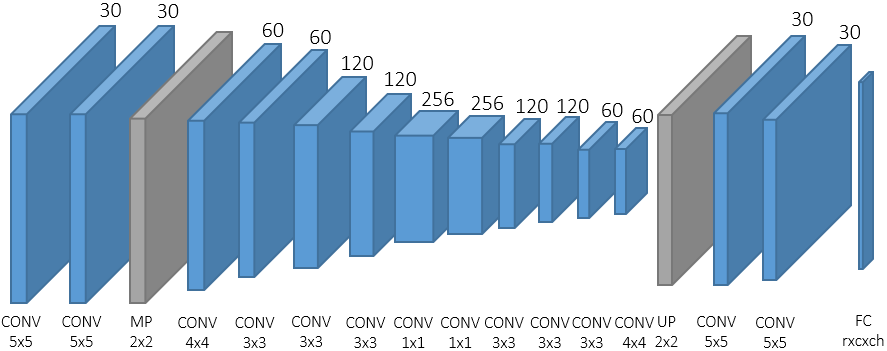

Face-from-Depth is one of the most innovative elements of the framework. Due to illumination issues, the appearance of the face is not always available in many scenarios, e.g. inside a vehicle. On the contrary, depth maps are invariant to illumination conditions but lacks of useful texture details. We aim at investigating if it is possible to imagine the appearance of a face given the corresponding depth data. Somehow, we are trying to emulate the behavior of a blind person when he tries to figure out the appearance of a friend through the touch. The Face-from-Depth network has been created to this goal, even if the output is not always realistic and visually pleasant. However, the promising results confirm their positive contribution in the estimation of the head pose.
Head Localization

Head and Shoulder Pose


The final goal is the estimation of the pose of the driver's head and shoulders, defined as the mass center position and the corresponding orientation relatively to the reference frame of the acquisition device. The orientation is represented using the three pitch, roll and yaw rotation angles. POSEidon directly processes the stream of depth frames captured in real time by a commercial sensor (e.g. Microsoft Kinect).
Video, Demo and Images of POSEidon framework and Pandora dataset
The attached video shows the output of the prototype system developed to test the driver pose estimation method.
The video proves the efficacy of the system and the real time perfomance capabilities.
Both in-car and laboratory sequences are included.