

Self-Supervised Navigation and Recounting
Advances in the field of embodied AI aim to foster the next generation of autonomous and intelligent robots. At the same time, tasks at the intersection of computer vision and natural language processing are of particular interest for the community, with image captioning being one of the most active areas. By describing the content of an image or a video, captioning models can bridge the gap between the black-box architecture and the user. In this project, we propose a new task at the intersection of embodied AI, computer vision, and natural language processing, and aim to create a robot that can navigate through a new environment and describe what it sees. We call this new task Explore and Explain since it tackles the problem of joint exploration and captioning. In this schema, the agent needs to perceive the environment around itself, navigate it driven by an exploratory goal, and describe salient objects and scenes in natural language. Beyond navigating the environment and translating visual cues in natural language, the agent also needs to identify appropriate moments to perform the explanation step.
Embodied Agents for Efficient Exploration and Smart Scene Description
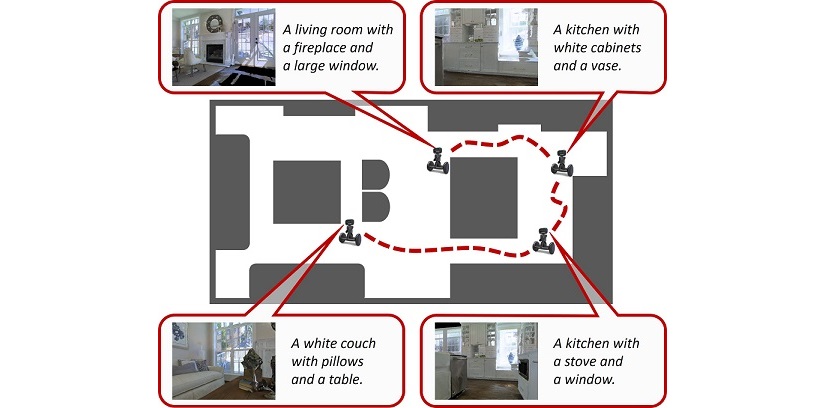
The development of embodied agents that can communicate with humans in natural language has gained increasing interest over the last years, as it facilitates the diffusion of robotic platforms in human-populated environments. As a step towards this objective, in this work, we tackle a setting for visual navigation in which an autonomous agent needs to explore and map an unseen indoor environment while portraying interesting scenes with natural language descriptions. To this end, we propose and evaluate an approach that combines recent advances in visual robotic exploration and image captioning on images generated through agent-environment interaction. Our approach can generate smart scene descriptions that maximize semantic knowledge of the environment and avoid repetitions. Further, such descriptions offer user-understandable insights into the robot's representation of the environment by highlighting the prominent objects and the correlation between them as encountered during the exploration. To quantitatively assess the performance of the proposed approach, we also devise a specific score that takes into account both exploration and description skills. The experiments carried out on both photorealistic simulated environments and real-world ones demonstrate that our approach can effectively describe the robot's point of view during exploration, improving the human-friendly interpretability of its observations.
Explore and Explain: Self-supervised Navigation and Recounting
Embodied AI has been recently gaining attention as it aims to foster the development of autonomous and intelligent agents. In this paper, we devise a novel embodied setting in which an agent needs to explore a previously unknown environment while recounting what it sees during the path. In this context, the agent needs to navigate the environment driven by an exploration goal, select proper moments for description, and output natural language descriptions of relevant objects and scenes. Our model integrates a novel self-supervised exploration module with penalty, and a fully-attentive captioning model for explanation. Also, we investigate different policies for selecting proper moments for explanation, driven by information coming from both the environment and the navigation. Experiments are conducted on photorealistic environments from the Matterport3D dataset and investigate the navigation and explanation capabilities of the agent as well as the role of their interactions.
SMArT: Training Shallow Memory-aware Transformers for Robotic Explainability
The ability to generate natural language explanations conditioned on the visual perception is a crucial step towards autonomous agents which can explain themselves and communicate with humans. While the research efforts in image and video captioning are giving promising results, this is often done at the expense of the computational requirements of the approaches, limiting their applicability to real contexts. In this paper, we propose a fully-attentive captioning algorithm which can provide state-of-the-art performances on language generation while restricting its computational demands. Our model is inspired by the Transformer model and employs only two Transformer layers in the encoding and decoding stages. Further, it incorporates a novel memory-aware encoding of image regions. Experiments demonstrate that our approach achieves competitive results in terms of caption quality while featuring reduced computational demands. Further, to evaluate its applicability on autonomous agents, we conduct experiments on simulated scenes taken from the perspective of domestic robots.

Paper

Embodied Agents for Efficient Exploration and Smart Scene Description
R.Bigazzi, M.Cornia, S.Cascianelli, L.Baraldi, R.Cucchiara
ICRA 2023
Publications
| 1 | Bigazzi, Roberto; Cornia, Marcella; Cascianelli, Silvia; Baraldi, Lorenzo; Cucchiara, Rita "Embodied Agents for Efficient Exploration and Smart Scene Description" Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), vol. 2023-May, London, pp. 6057 -6064 , 29 May - 2 June 2023, 2023 | DOI: 10.1109/ICRA48891.2023.10160668 Conference |
| 2 |
Bigazzi, Roberto; Landi, Federico; Cornia, Marcella; Cascianelli, Silvia; Baraldi, Lorenzo; Cucchiara, Rita
"Explore and Explain: Self-supervised Navigation and Recounting"
Proceedings of the 25th International Conference on Pattern Recognition,
Milan, Italy,
pp. 1152
-1159
,
10-15 January 2021,
2021
| DOI: 10.1109/ICPR48806.2021.9412628
Conference

|
| 3 |
Cornia, Marcella; Baraldi, Lorenzo; Cucchiara, Rita
"SMArT: Training Shallow Memory-aware Transformers for Robotic Explainability"
International Conference on Robotics and Automation,
Paris, France,
pp. 1128
-1134
,
May, 31 - June, 4,
2020
Conference
|
